
लोकप्रिय बड़े भाषा मॉडलों के लिए अंतिम मार्गदर्शिका
कल्पना कीजिए कि आप सही कहानी लिखने के लिए संघर्ष कर रहे हैं, आपकी उंगलियां कीबोर्ड पर घूम रही हैं और खाली पेज आपको चिढ़ा रहा है। अचानक, आपको अपना गुप्त हथियार याद आता है: एक बड़ा भाषा मॉडल (एलएलएम)। कुछ संकेतों के साथ, एलएलएम एक ऐसी मनोरम कहानी बुनता है, जो जादू जैसी लगती है। यह एलएलएम, परिष्कृत एआई सिस्टम की शक्ति का सिर्फ एक उदाहरण है जो प्रौद्योगिकी के साथ हमारे बातचीत करने के तरीके को नया आकार दे रहा है।
आर्टिफिशियल इंटेलिजेंस (एआई) की लगातार बदलती और दिलचस्प दुनिया में, बड़े भाषा मॉडल (एलएलएम) मानव भाषा को संभालने में अपनी प्रभावशाली क्षमताओं के साथ लहरें पैदा कर रहे हैं। लेकिन ये एलएलएम वास्तव में क्या हैं, और ये हमारी दैनिक बातचीत और कार्यों में कैसे क्रांतिकारी बदलाव लाते हैं? आइए इस मनोरम क्षेत्र में उतरें और एआई के भविष्य को आकार देने वाले कुछ सबसे प्रमुख एलएलएम को उजागर करें।
बड़े भाषा मॉडल को समझना
एलएलएम उन्नत मशीन लर्निंग मॉडल हैं जो मानव-जैसे पाठ की भविष्यवाणी करते हैं और उत्पन्न करते हैं। वे वाक्यों को स्वत: पूर्ण कर सकते हैं, भाषाओं का अनुवाद कर सकते हैं और यहां तक कि संपूर्ण लेख भी तैयार कर सकते हैं। ये मॉडल सरल शब्द भविष्यवक्ताओं से लेकर पैराग्राफ और दस्तावेज़ों को संभालने में सक्षम जटिल प्रणालियों तक विकसित हुए हैं।
बड़े भाषा मॉडल कैसे काम करते हैं?
एलएलएम भाषा पैटर्न सीखने के लिए विशाल डेटासेट का उपयोग करके शब्दों के अनुक्रम की संभावना का अनुमान लगाते हैं। वे ट्रांसफॉर्मर जैसे आर्किटेक्चर पर बनाए गए हैं, जो लंबे अनुक्रमों को कुशलतापूर्वक संसाधित करने के लिए इनपुट के सबसे प्रासंगिक भागों पर ध्यान केंद्रित करते हैं।
एलएलएम का विकास: बीईआरटी से जीपीटी-4 तक
2018 में Google द्वारा पेश किया गया BERT, भाषा की बारीकियों को समझने के लिए द्विदिश संदर्भ का उपयोग करते हुए एक सफलता थी। GPT-4, अपने 178 बिलियन मापदंडों के साथ, मानव-जैसा पाठ उत्पन्न करने की क्षमता का प्रदर्शन करते हुए, पाठ निर्माण को नई ऊंचाइयों पर ले गया।
क्रियाशील बड़े भाषा मॉडल के उदाहरण
चैटजीपीटी, ओपनएआई के जीपीटी मॉडल का एक प्रकार, एक घरेलू नाम बन गया है, जो मानव-जैसी बातचीत की पेशकश करने वाले चैटबॉट्स को सशक्त बनाता है।
प्राकृतिक भाषा प्रसंस्करण कार्यों पर BERT का प्रभाव
BERT ने भावना विश्लेषण और भाषा अनुवाद जैसे प्राकृतिक भाषा प्रसंस्करण कार्यों के प्रदर्शन में काफी सुधार किया है।
GPT-3 और टेक्स्ट जनरेशन की सीमा
GPT-3 की रचनात्मक और सुसंगत पाठ उत्पन्न करने की क्षमता ने सामग्री निर्माण और उससे परे नई संभावनाओं को खोल दिया है।
आज के प्रमुख बड़े भाषा मॉडलों की तुलना के लिए एक चीट शीट
बड़े भाषा मॉडलों के परिमाण और विविधता को बेहतर ढंग से समझने के लिए, आइए वर्तमान में परिदृश्य पर हावी होने वाले सार्वजनिक रूप से उपलब्ध कुछ सबसे प्रभावशाली मॉडलों पर करीब से नज़र डालें। प्रत्येक मॉडल विभिन्न उपयोग के मामलों में अद्वितीय ताकत और उत्कृष्टता लाता है।
यह तालिका 2024 तक के कुछ सबसे प्रभावशाली बड़े भाषा मॉडलों का त्वरित अवलोकन प्रदान करती है। Google द्वारा पेश किया गया BERT, अपने ट्रांसफार्मर-आधारित वास्तुकला के लिए जाना जाता है और प्राकृतिक भाषा प्रसंस्करण कार्यों में एक महत्वपूर्ण प्रगति थी। क्लाउडएंथ्रोपिक द्वारा विकसित, संवैधानिक एआई पर केंद्रित है, जिसका लक्ष्य एआई आउटपुट को सहायक, हानिरहित और सटीक बनाना है। जुटनाएक एंटरप्राइज एलएलएम, विशिष्ट कंपनी उपयोग मामलों के लिए कस्टम प्रशिक्षण और फाइन-ट्यूनिंग प्रदान करता है। Baidu के एर्नी के पास आश्चर्यजनक 10 ट्रिलियन पैरामीटर हैं और उसे मंदारिन में उत्कृष्टता प्राप्त करने के लिए डिज़ाइन किया गया है, लेकिन वह अन्य भाषाओं में भी सक्षम है।
Local LLMs vs Cloud LLMs
While cloud-based LLMs offer impressive capabilities, a growing trend is the use of local inference with open-source models. Tools like LM Studio allow users to run run LLMs locally directly on their machines.
This approach prioritizes privacy by keeping all data and processing offline. However, local inference typically requires more powerful hardware and may limit access to the most cutting-edge models due to their size.
शीर्ष 15 लोकप्रिय बड़े भाषा मॉडल
| मॉडल नाम | आकार (पैरामीटर) | खुला स्त्रोत? | अंतिम अद्यतन (अनुमानित) | कंपनी | विकास का देश |
| AI21 स्टूडियो जुरासिक-1 जंबो | 178बी | हाँ | दिसंबर 2022 | AI21 स्टूडियो | इजराइल |
| गूगल जेम्मा | 2बी या 7बी | हाँ | मई 2023 | गूगल एआई | संयुक्त राज्य अमेरिका |
| मेटा लामा 13बी | 13बी | हाँ | 2023 की शुरुआत में | मेटा एआई | संयुक्त राज्य अमेरिका |
| मेटा LLaMA 7B | 7 बी | हाँ | 2023 की शुरुआत में | मेटा एआई | संयुक्त राज्य अमेरिका |
| एलुथेरएआई जीपीटी-जे | 6बी | हाँ | मई 2023 (डॉली 2 जैसे कांटे के माध्यम से) | एलुथेरएआई (अनुसंधान समूह) | संयुक्त राज्य अमेरिका |
| ढेर – EleutherAI | 900GB टेक्स्ट डेटा | हाँ | जारी विकास | एलुथेरएआई (अनुसंधान समूह) | संयुक्त राज्य अमेरिका |
| मिस्ट्रल एआई – मिस्ट्रल लार्ज | सार्वजनिक रूप से खुलासा नहीं किया गया (बड़ा) | सशुल्क विकल्पों के साथ ओपन-सोर्स | सितंबर 2023 | मिस्ट्रल ए.आई | फ्रांस |
| फाल्कन 180बी | 180बी | हाँ | निर्दिष्ट नहीं है | प्रौद्योगिकी नवाचार संस्थान | संयुक्त अरब अमीरात |
| बर्ट | 342 मिलियन | नहीं | जुलाई 2018 | गूगल एआई | संयुक्त राज्य अमेरिका |
| एर्नी | 10 ट्रिलियन | नहीं | अगस्त 2023 | Baidu | चीन |
| ओपनएआई जीपीटी-3.5 | 175बी | नहीं | 2022 के अंत में | ओपनएआई | संयुक्त राज्य अमेरिका |
| क्लाउड | निर्दिष्ट नहीं है | नहीं | निर्दिष्ट नहीं है | anthropic | संयुक्त राज्य अमेरिका |
| जुटना | सार्वजनिक रूप से खुलासा नहीं किया गया (बड़े पैमाने पर) | नहीं | सतत विकास | जुटना | कनाडा |
| Google PaLM (अनुसंधान फोकस) | सार्वजनिक रूप से खुलासा नहीं किया गया (संभवतः बहुत बड़ा) | नहीं | अल्प विकास | गूगल एआई | संयुक्त राज्य अमेरिका |
| ओपनएआई जीपीटी-4 | सार्वजनिक रूप से खुलासा नहीं किया गया (जीपीटी-3.5 का उत्तराधिकारी) | नहीं | अल्प विकास | ओपनएआई | संयुक्त राज्य अमेरिका |
एलएलएम विकास के देश की तुलना
शीर्ष 15 बड़े भाषा मॉडल (एलएलएम) की तुलना करते समय, संयुक्त राज्य अमेरिका 15 में से 10 द्वारा एलएलएम विकास बाजार हिस्सेदारी में लगभग 67% का योगदान देता है।
| विकास का देश | मॉडलों की संख्या |
| कनाडा | 1 |
| चीन | 1 |
| फ्रांस | 1 |
| इजराइल | 1 |
| संयुक्त अरब अमीरात | 1 |
| संयुक्त राज्य अमेरिका | 10 |
| कुल योग | 15 |

एलएलएम आर्किटेक्चर और प्रशिक्षण विधियाँ
| वास्तुकला/विधि | विवरण |
|---|---|
| ट्रांसफार्मर | एक तंत्रिका नेटवर्क आर्किटेक्चर जो अनुक्रमिक डेटा को संसाधित करने की दक्षता और सटीकता में सुधार करने के लिए ध्यान तंत्र पर निर्भर करता है। यह कई आधुनिक एलएलएम की नींव है। |
| पूर्व प्रशिक्षण | एलएलएम के प्रशिक्षण का प्रारंभिक चरण, इसमें भाषा के सांख्यिकीय पैटर्न और संरचनाओं को सीखने के लिए बड़ी मात्रा में बिना लेबल वाले पाठ डेटा को उजागर करना शामिल है। |
| फ़ाइन ट्यूनिंग | किसी विशेष कार्य से संबंधित विशिष्ट डेटा पर प्रशिक्षण देकर पूर्व प्रशिक्षित मॉडल को परिष्कृत करना, उस कार्य के लिए उसके प्रदर्शन को बढ़ाना। |
| QLoRA | कुशल फाइन-ट्यूनिंग को सक्षम करने के लिए लो रैंक एडेप्टर (एलओआरए) में जमे हुए, 4-बिट क्वांटाइज्ड पूर्व-प्रशिक्षित भाषा मॉडल के माध्यम से बैकप्रोपेगेटिंग ग्रेडिएंट्स को शामिल करने वाली एक विधि। |
ट्रांसफॉर्मर आर्किटेक्चर ने मॉडलों को डेटा के लंबे अनुक्रमों को अधिक प्रभावी ढंग से संभालने में सक्षम बनाकर प्राकृतिक भाषा प्रसंस्करण के क्षेत्र में क्रांति ला दी है। एलएलएम के विकास में पूर्व-प्रशिक्षण और फाइन-ट्यूनिंग महत्वपूर्ण चरण हैं, जो उन्हें विशाल मात्रा में डेटा से सीखने और फिर विशिष्ट कार्यों में विशेषज्ञता प्रदान करते हैं। QLoRA एलएलएम को बेहतर बनाने के लिए एक उन्नत तकनीक का प्रतिनिधित्व करता है, जो प्रदर्शन को बनाए रखते हुए मेमोरी की मांग को कम करता है
बड़े भाषा मॉडल के लिए मुख्य उपयोग के मामले
कैसे एलएलएम भाषा अनुवाद और भावना विश्लेषण में क्रांति लाते हैं
एलएलएम ने बड़ी मात्रा में डेटा को समझने और अनुवाद करके भाषा अनुवाद को बदल दिया है, जबकि उनकी गहन सीखने की क्षमताओं के कारण भावना विश्लेषण अधिक सूक्ष्म हो गया है।
चैटबॉट्स के साथ मानव-मशीन इंटरैक्शन को बढ़ाना
एलएलएम द्वारा संचालित चैटबॉट व्यक्तिगत और कुशल ग्राहक सहायता प्रदान करते हैं, जिससे ग्राहक सेवा का स्वरूप बदल जाता है।
जेनरेटिव एआई के माध्यम से सामग्री निर्माण में परिवर्तन
GPT-3 जैसे जनरेटिव AI मॉडल ने लेखकों और डिजाइनरों को समान रूप से सहायता करते हुए शीघ्रता से उच्च गुणवत्ता वाली सामग्री बनाना संभव बना दिया है।
एलएलएम को लागू करने की चुनौतियाँ और सीमाएँ
पूर्वाग्रह और नैतिक उपयोग से संबंधित चिंताओं को संबोधित करना
एलएलएम के लिए प्रशिक्षण डेटा पूर्वाग्रह पैदा कर सकता है, नैतिक चिंताएं बढ़ा सकता है जिनका समाधान किया जाना चाहिए।
बड़े मॉडलों के प्रशिक्षण की कम्प्यूटेशनल लागत को समझना
एलएलएम के प्रशिक्षण के लिए महत्वपूर्ण कम्प्यूटेशनल संसाधनों की आवश्यकता होती है, जो महंगा और पर्यावरण की दृष्टि से टिकाऊ नहीं हो सकता है।
भाषा की समझ और संदर्भ को समझने में सीमाएँ
अपनी क्षमताओं के बावजूद, एलएलएम अभी भी मानव भाषा के संदर्भ और सूक्ष्मताओं को समझने में संघर्ष करते हैं।
बड़े भाषा मॉडलों को कैसे प्रशिक्षित और परिष्कृत किया जाता है
प्री-ट्रेनिंग एलएलएम में बड़ी मात्रा में डेटा का महत्व
एलएलएम को भाषा पैटर्न और बारीकियों की एक विस्तृत श्रृंखला सीखने के लिए बड़े डेटासेट की आवश्यकता होती है।
विशिष्ट अनुप्रयोगों के लिए फ़ाइन-ट्यूनिंग तकनीकें
एलएलएम को विशिष्ट कार्यों के लिए अनुकूलित करने के लिए ट्रांसफॉर्मर मॉडल के साथ ट्रांसफर लर्निंग और फाइन-ट्यूनिंग जैसी तकनीकों का उपयोग किया जाता है।
मशीन लर्निंग में आधारभूत मॉडल का उद्भव
फाउंडेशन मॉडल मशीन लर्निंग में एक नया चलन है, जो विशेष मॉडल बनाने के लिए आधार प्रदान करता है।
पूर्व-प्रशिक्षण और कार्य-विशिष्ट प्रशिक्षण के बीच अंतर
बड़े भाषा मॉडल (एलएलएम) के विकास में पूर्व-प्रशिक्षण और कार्य-विशिष्ट प्रशिक्षण (अक्सर फाइन-ट्यूनिंग के रूप में जाना जाता है) दो महत्वपूर्ण चरण हैं। ये चरण इस बात पर आधारित हैं कि एलएलएम मानव-जैसे पाठ को कैसे समझते हैं और उत्पन्न करते हैं, प्रत्येक मॉडल की सीखने की प्रक्रिया में एक अलग उद्देश्य की पूर्ति करता है।
एलएलएम का पूर्व प्रशिक्षण
पूर्व-प्रशिक्षण प्रारंभिक, व्यापक चरण है जहां एलएलएम टेक्स्ट डेटा के विशाल संग्रह से सीखता है। यह चरण मॉडल को भाषा, संस्कृति और सामान्य ज्ञान पर व्यापक शिक्षा देने के समान है। यहां पूर्व-प्रशिक्षण के प्रमुख पहलू दिए गए हैं:
- सामान्य ज्ञानकोष: मॉडल पाठ के एक बड़े संग्रह का विश्लेषण करके व्याकरण, मुहावरों, तथ्यों और संदर्भ की समझ विकसित करता है। यह व्यापक ज्ञान आधार मॉडल को सुसंगत और प्रासंगिक रूप से उपयुक्त प्रतिक्रियाएँ उत्पन्न करने में सक्षम बनाता है।
- स्थानांतरण सीखना: पूर्व-प्रशिक्षित मॉडल अपने सीखे गए भाषा पैटर्न को नए डेटासेट पर लागू कर सकते हैं, विशेष रूप से सीमित डेटा वाले कार्यों के लिए उपयोगी। यह क्षमता व्यापक कार्य-विशिष्ट डेटा की आवश्यकता को काफी कम कर देती है।
- लागत प्रभावशीलता: पूर्व-प्रशिक्षण के लिए आवश्यक पर्याप्त कम्प्यूटेशनल संसाधनों के बावजूद, एक ही मॉडल को विभिन्न अनुप्रयोगों में पुन: उपयोग किया जा सकता है, जिससे यह एक लागत प्रभावी दृष्टिकोण बन जाता है।
- लचीलापन और मापनीयता: पूर्व-प्रशिक्षण के दौरान प्राप्त व्यापक समझ एक ही मॉडल को विविध कार्यों के लिए अनुकूलित करने की अनुमति देती है। इसके अतिरिक्त, जैसे ही नया डेटा उपलब्ध होता है, पूर्व-प्रशिक्षित मॉडल को उनके प्रदर्शन को बेहतर बनाने के लिए और प्रशिक्षित किया जा सकता है।
कार्य-विशिष्ट प्रशिक्षण (फाइन-ट्यूनिंग)
पूर्व-प्रशिक्षण के बाद, मॉडल फाइन-ट्यूनिंग से गुजरते हैं, जहां उन्हें छोटे, कार्य-विशिष्ट डेटासेट पर प्रशिक्षित किया जाता है। यह चरण विशेष कार्यों पर अच्छा प्रदर्शन करने के लिए मॉडल के व्यापक ज्ञान को तैयार करता है। फ़ाइन-ट्यूनिंग के प्रमुख पहलुओं में शामिल हैं:
- कार्य विशेषज्ञताफाइन-ट्यूनिंग पूर्व-प्रशिक्षित मॉडलों को विशिष्ट कार्यों या उद्योगों के अनुकूल बनाती है, जिससे विशेष अनुप्रयोगों पर उनका प्रदर्शन बेहतर होता है।
- डेटा दक्षता और गति: चूंकि मॉडल ने पूर्व-प्रशिक्षण के दौरान पहले से ही सामान्य भाषा पैटर्न सीख लिया है, विशिष्ट कार्यों के लिए मॉडल को विशेषज्ञ बनाने के लिए फाइन-ट्यूनिंग के लिए कम डेटा और समय की आवश्यकता होती है।
- मॉडल अनुकूलन: फाइन-ट्यूनिंग विभिन्न कार्यों की अनूठी आवश्यकताओं को पूरा करने के लिए मॉडल के अनुकूलन की अनुमति देता है, जिससे यह विशिष्ट अनुप्रयोगों के लिए अत्यधिक अनुकूलनीय हो जाता है।
- संसाधन क्षमता: फाइन-ट्यूनिंग सीमित कम्प्यूटेशनल संसाधनों वाले अनुप्रयोगों के लिए विशेष रूप से फायदेमंद है, क्योंकि यह पूर्व-प्रशिक्षण के दौरान किए गए भारी भारोत्तोलन का लाभ उठाता है।
संक्षेप में, पूर्व-प्रशिक्षण एलएलएम को भाषा और सामान्य ज्ञान की व्यापक समझ से लैस करता है, जबकि फाइन-ट्यूनिंग इस ज्ञान को विशिष्ट कार्यों में उत्कृष्टता प्राप्त करने के लिए तैयार करता है। पूर्व-प्रशिक्षण मॉडल की भाषा क्षमताओं के लिए आधार तैयार करता है, और फाइन-ट्यूनिंग लक्षित अनुप्रयोगों के लिए इन क्षमताओं को अनुकूलित करता है, विशेषज्ञता के साथ मॉडल के सामान्यीकरण को संतुलित करता है।
बड़े भाषा मॉडल का भविष्य
अगली पीढ़ी के एलएलएम की आशा: जीपीटी-4 और उससे आगे
की अगली पीढ़ी एलएलएम, जीपीटी की तरह-4 से एआई में जो संभव है उसकी सीमाओं को और भी आगे बढ़ाने की उम्मीद है।
UberCreate AI आर्टिकल विज़ार्ड एक शक्तिशाली उपकरण है जो मिनटों में उच्च गुणवत्ता वाले लेख तैयार करने के लिए OpenAI GPT-4 बड़े भाषा मॉडल (LLM) का लाभ उठाता है।
UberCreate के साथ, आप राइटर ब्लॉक को अलविदा कह सकते हैं और मिनटों में एक विस्तृत लेख पढ़ सकते हैं। आपको बस एक विषय, एक कीवर्ड और एक लक्ष्य शब्द गणना प्रदान करने की आवश्यकता है, और UberCreate बाकी का ध्यान रखेगा। यह एक लेख की रूपरेखा, चर्चा के बिंदु, प्रासंगिक चित्र और एक अंतिम लेख तैयार करेगा जो प्रकाशित करने के लिए तैयार है।
GPT-4 का उपयोग करके UberCreate AI आर्टिकल विज़ार्ड
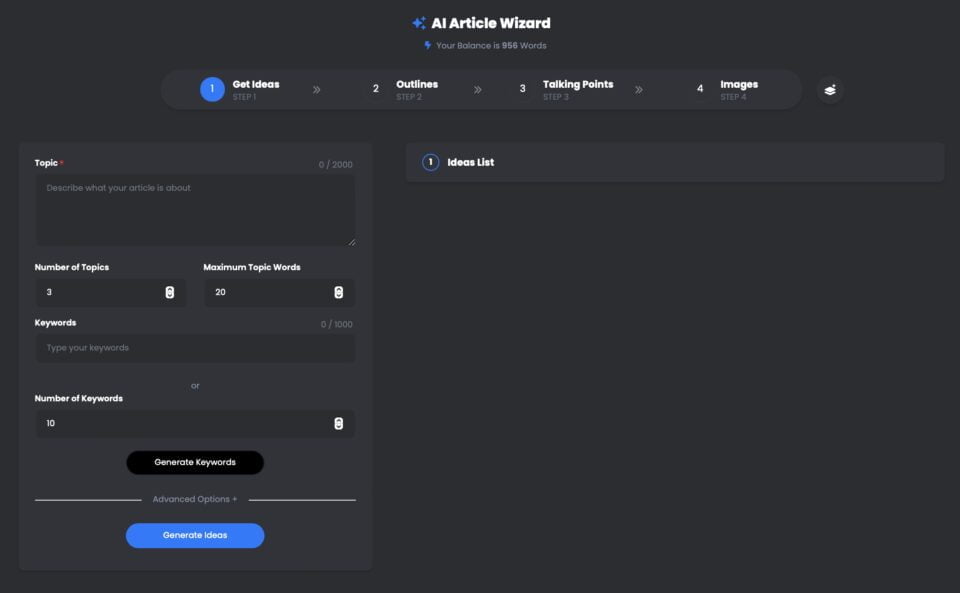 Pin
Pin UberCreate मौलिक, आकर्षक और जानकारीपूर्ण सामग्री बनाने के लिए उन्नत कृत्रिम बुद्धिमत्ता तकनीक का उपयोग करता है। यह व्यवसाय और मार्केटिंग से लेकर स्वास्थ्य और जीवनशैली तक किसी भी विषय पर लिख सकता है। यह आपकी प्राथमिकताओं और आवश्यकताओं के आधार पर विभिन्न टोन, शैलियों और प्रारूपों के अनुकूल भी हो सकता है।
UberCreate केवल एक सामग्री जनरेटर नहीं है, बल्कि एक सामग्री बढ़ाने वाला भी है। यह अधिक विवरण, तथ्य और चित्र जोड़कर आपके मौजूदा लेखों को बेहतर बनाने में आपकी सहायता कर सकता है। यह आपके व्याकरण, वर्तनी और पठनीयता की भी जांच कर सकता है और एसईओ और सोशल मीडिया के लिए आपकी सामग्री को अनुकूलित करने के तरीके सुझा सकता है।
UberCreate एकमात्र AI सामग्री निर्माण उपकरण है जिसकी आपको कभी भी आवश्यकता होगी। यह 17 AI टूल को एक साथ जोड़ता है, जिसमें एक ब्लॉग पोस्ट जनरेटर, एक सोशल मीडिया सामग्री जनरेटर, एक विज़ुअल सामग्री जनरेटर और बहुत कुछ शामिल है। इसे विचार-विमर्श से लेकर उत्पादन तक, सामग्री निर्माण के हर पहलू को सुविधाजनक बनाने के लिए डिज़ाइन किया गया है।
चाहे आप ब्लॉगर हों, मार्केटर हों, छात्र हों या पेशेवर हों, UberCreate आपको उच्च गुणवत्ता वाली सामग्री बनाने में समय, पैसा और प्रयास बचाने में मदद कर सकता है। आप इसे निःशुल्क आज़मा सकते हैं और परिणाम स्वयं देख सकते हैं।
मानव-एआई सहयोग की सीमाओं का विस्तार
LLMs एलएलएम मनुष्यों और एआई के बीच सहयोग बढ़ाने के लिए तैयार हैं, जिससे बातचीत अधिक प्राकृतिक और उत्पादक बन जाएगी।
जब प्रौद्योगिकी के साथ हमारी बातचीत में क्रांति लाने और मानव-एआई सहयोग की सीमाओं का विस्तार करने में बड़े भाषा मॉडल की विशाल क्षमता को समझने की बात आती है, तो ये प्रमुख एलएलएम हिमशैल का टिप मात्र हैं। इस श्रृंखला के भाग II के लिए बने रहें, जहां हम बड़े भाषा मॉडल की क्षमताओं, विभिन्न उद्योगों में उनके अनुप्रयोगों और उनकी शक्ति के दोहन के साथ आने वाली चुनौतियों के बारे में गहराई से जानेंगे।
आने वाले दशक में प्राकृतिक भाषा समझने की संभावनाएँ
एलएलएम अधिक परिष्कृत और विभिन्न अनुप्रयोगों में एकीकृत होने के साथ, प्राकृतिक भाषा समझ का भविष्य उज्ज्वल दिखता है।
निष्कर्ष के तौर पर, बीईआरटी, जीपीटी-3 जैसे एलएलएम और उनके उत्तराधिकारी शिक्षा से लेकर स्वास्थ्य सेवा तक उद्योगों में क्रांति ला रहे हैं। जैसे-जैसे हम उनकी शक्ति का उपयोग करना जारी रखते हैं, हमें उनके नैतिक और जिम्मेदार उपयोग को सुनिश्चित करते हुए उनके द्वारा प्रस्तुत चुनौतियों का भी सामना करना चाहिए। बड़े भाषा मॉडलों की दुनिया में यात्रा अभी शुरू हो रही है, और संभावनाएं उतनी ही विशाल हैं जितनी कि वे डेटासेट जिनसे वे सीखते हैं। इस रोमांचक क्षेत्र में उतरें, और आइए मिलकर AI के भविष्य को आकार दें।
अक्सर पूछे जाने वाले प्रश्न (एफएक्यू)
एनएलपी के संदर्भ में लार्ज लैंग्वेज मॉडल (एलएलएम) क्या है?
प्राकृतिक भाषा प्रसंस्करण (एनएलपी) के दायरे में एक बड़ा भाषा मॉडल (एलएलएम), एक उन्नत एआई प्रणाली को संदर्भित करता है जिसे मानव-जैसे पाठ को समझने, व्याख्या करने और उत्पन्न करने के लिए डिज़ाइन किया गया है। इन मॉडलों को बड़ी मात्रा में डेटा पर प्रशिक्षित किया जाता है, जो उन्हें भाषा संबंधी कार्यों की एक विस्तृत श्रृंखला करने में सक्षम बनाता है। प्रशिक्षण की प्रक्रिया के माध्यम से, मॉडल एक वाक्य में अगले शब्द की भविष्यवाणी करना सीखता है, जिससे उसे मांग पर सुसंगत और प्रासंगिक रूप से प्रासंगिक पाठ उत्पन्न करने में मदद मिलती है।
2024 में विभिन्न प्रकार के एलएलएम कौन से उपलब्ध हैं?
2024 तक, कई अलग-अलग प्रकार के बड़े भाषा मॉडल उपलब्ध हैं, जिनमें से प्रत्येक में अद्वितीय क्षमताएं हैं। सबसे उल्लेखनीय में GPT-4 जैसे मॉडल शामिल हैं, जो अपनी जेनरेटिव टेक्स्ट क्षमताओं के लिए जाना जाता है और बार्ड, जो Google का समकक्ष है जो एनएलपी कार्यों की एक विस्तृत श्रृंखला पर ध्यान केंद्रित करता है। ये मॉडल मापदंडों की संख्या, डेटा जिस पर उन्हें प्रशिक्षित किया गया था और उनके विशिष्ट अनुप्रयोगों में भिन्न हैं, सरल पाठ निर्माण से लेकर जटिल भाषा समझ कार्यों तक।
एलएलएम को बड़े डेटासेट पर कैसे प्रशिक्षित किया जाता है?
एलएलएम को पुस्तकों, लेखों और वेबसाइटों सहित इंटरनेट से एकत्र किए गए विशाल डेटासेट का उपयोग करके प्रशिक्षित किया जाता है। इस व्यापक प्रशिक्षण प्रक्रिया में मॉडल को बड़ी मात्रा में टेक्स्ट डेटा फीड करना शामिल है, जो मॉडल को पैटर्न की पहचान करने, संदर्भ को समझने और भाषा संरचनाओं को सीखने में मदद करता है। मॉडल के आकार और उपलब्ध कम्प्यूटेशनल संसाधनों के आधार पर प्रशिक्षण प्रक्रिया में सप्ताह या महीने भी लग सकते हैं। इसका उद्देश्य मॉडल को ऐसे पाठ उत्पन्न करने में सक्षम बनाना है जो मनुष्यों द्वारा लिखे गए पाठ से अप्रभेद्य हो।
क्या आप रोजमर्रा के कार्यों में एलएलएम के अनुप्रयोगों की व्याख्या कर सकते हैं?
एलएलएम का उपयोग रोजमर्रा के कार्यों को सरल और स्वचालित करने के लिए विभिन्न अनुप्रयोगों में किया जा सकता है। इसमें ग्राहक सेवा के लिए चैटबॉट और वर्चुअल असिस्टेंट, लेख या रिपोर्ट तैयार करने के लिए सामग्री निर्माण उपकरण और भाषाओं के बीच पाठ को परिवर्तित करने के लिए अनुवाद सेवाएं शामिल हैं। अन्य अनुप्रयोगों में सोशल मीडिया पर जनता की राय जानने के लिए भावना विश्लेषण, लंबे दस्तावेज़ों को छोटे संस्करणों में संक्षिप्त करने के लिए सारांश उपकरण और यहां तक कि कोड स्निपेट उत्पन्न करके प्रोग्रामर की मदद करने के लिए कोडिंग सहायक भी शामिल हैं। अनिवार्य रूप से, एलएलएम ने प्रौद्योगिकी के साथ हमारी बातचीत के तरीके में क्रांति ला दी है, जिससे यह अधिक सहज और मानवीय बन गई है।
बड़े भाषा मॉडल की क्षमताएं पारंपरिक मॉडल से किस प्रकार भिन्न हैं?
बड़े भाषा मॉडल कई मायनों में पारंपरिक मॉडल से बेहतर प्रदर्शन करते हैं। सबसे पहले, विविध डेटासेट पर उनके व्यापक प्रशिक्षण के कारण, एलएलएम अधिक सुसंगत, विविध और प्रासंगिक रूप से उपयुक्त प्रतिक्रियाएं उत्पन्न कर सकते हैं। वे भाषा की बारीकियों को बेहतर ढंग से समझते हैं और अनुक्रमिक डेटा को अधिक कुशलता से संभाल सकते हैं। इसके अलावा, एलएलएम में मापदंडों की विशाल संख्या पारंपरिक मॉडलों की तुलना में अधिक परिष्कृत तर्क और पूर्वानुमान क्षमताओं को सक्षम बनाती है, जो दायरे और स्केलेबिलिटी में अधिक सीमित थे। अंततः, एलएलएम भाषा के प्रसंस्करण और निर्माण के लिए अधिक सूक्ष्म और बहुमुखी दृष्टिकोण प्रदान करते हैं।
एलएलएम के विकास और तैनाती से जुड़ी चुनौतियाँ क्या हैं?
एलएलएम का विकास और तैनाती प्रशिक्षण के लिए आवश्यक कम्प्यूटेशनल संसाधनों सहित कई चुनौतियाँ पेश करती है, जो पर्याप्त हो सकती हैं। इसके अतिरिक्त, प्रशिक्षण डेटा में पूर्वाग्रह के संबंध में चिंताएं हैं, जो मॉडल को पूर्वाग्रहित या हानिकारक सामग्री उत्पन्न करने के लिए प्रेरित कर सकती हैं। प्रशिक्षण में उपयोग किए गए डेटा की संवेदनशीलता से गोपनीयता के मुद्दे भी उत्पन्न होते हैं। इसके अलावा, इन मॉडलों की व्याख्या एक चुनौती खड़ी करती है, क्योंकि उनकी निर्णय लेने की प्रक्रिया जटिल है और हमेशा पारदर्शी नहीं होती है। अंत में, ऊर्जा-गहन प्रशिक्षण प्रक्रिया का पर्यावरणीय प्रभाव एक बढ़ती चिंता का विषय है।
GPT-4 और बार्ड जैसे भाषा मॉडल एनएलपी के क्षेत्र को कैसे प्रभावित करते हैं?
जीपीटी-4 और बार्ड जैसे मॉडलों ने एनएलपी कार्यों की एक विस्तृत श्रृंखला पर अभूतपूर्व प्रदर्शन करके प्राकृतिक भाषा प्रसंस्करण के क्षेत्र को महत्वपूर्ण रूप से उन्नत किया है। पाठ उत्पन्न करने, संदर्भ को समझने और मानव-जैसी प्रतिक्रियाएँ उत्पन्न करने की उनकी क्षमता ने भाषा को समझने और उत्पन्न करने में एआई क्या हासिल कर सकता है, इसके लिए नए मानक स्थापित किए हैं। इन मॉडलों ने न केवल चैटबॉट्स, सामग्री निर्माण और भाषा अनुवाद जैसे अनुप्रयोगों की गुणवत्ता और दक्षता को बढ़ाया है, बल्कि एआई क्षमताओं की सीमाओं को आगे बढ़ाते हुए एनएलपी में अनुसंधान और विकास के लिए नए रास्ते भी खोले हैं।
क्या एलएलएम को समझने और उसके साथ काम करने के लिए कोई शुरुआती मार्गदर्शिका है?
हां, इस क्षेत्र में नए लोगों के लिए, बड़े भाषा मॉडल के लिए शुरुआती मार्गदर्शिका अविश्वसनीय रूप से सहायक हो सकती है। इस तरह की मार्गदर्शिका आम तौर पर एलएलएम क्या हैं, उन्हें कैसे प्रशिक्षित किया जाता है, और उनके अनुप्रयोगों की मूल बातें शामिल करती हैं। यह 2023 में सबसे महत्वपूर्ण मॉडलों में अंतर्दृष्टि प्रदान कर सकता है, अंतर्निहित तकनीक की व्याख्या कर सकता है, और एनएलपी कार्यों के उदाहरण प्रदान कर सकता है जिन्हें एलएलएम के साथ किया जा सकता है। शुरुआत करने वाले ऑनलाइन संसाधनों, ट्यूटोरियल और पाठ्यक्रमों की तलाश कर सकते हैं जो इन अवधारणाओं का परिचय देते हैं, जिससे एलएलएम कैसे काम करते हैं और विभिन्न परियोजनाओं में उनका उपयोग कैसे किया जा सकता है, इसकी मूलभूत समझ बनाने में मदद मिलती है।


