
Os audiolivros tornaram-se cada vez mais populares nos últimos anos devido à sua conveniência e compatibilidade com o estilo de vida moderno. Seja ouvindo durante seu deslocamento diário ou enquanto realiza tarefas domésticas, os audiolivros permitem que as pessoas mergulhem em suas histórias favoritas enquanto estão em trânsito.
No entanto, a criação de um audiolivro normalmente requer um investimento significativo de tempo e dinheiro. É aqui que entra a tecnologia de conversão de texto em fala, fornecendo uma solução inovadora para autores e editores.
O que é texto em fala?
Text to Speech é uma tecnologia que permite que texto escrito seja convertido em palavras faladas. Isto é conseguido através de um processo chamado síntese de voz, que utiliza vários algoritmos e bancos de dados de voz para gerar uma fala realista e semelhante à humana. A tecnologia de conversão de texto em fala tem sido usada para uma variedade de aplicações, incluindo tradução de idiomas, acessibilidade e, agora, criação de audiolivros.
Como funciona o texto para fala?
A conversão de texto em fala funciona analisando o texto escrito e dividindo-o em unidades fonéticas individuais, chamadas fonemas. Esses fonemas são então combinados para criar palavras, frases e, por fim, o texto falado. Software de conversão de texto em fala utiliza aprendizado de máquina para melhorar continuamente a precisão e a naturalidade da voz sintetizada, resultando em vozes de IA mais realistas ao longo do tempo.
Componentes de um sistema TTS
Um sistema TTS consiste em dois componentes principais: análise de texto e síntese de fala.
- Análise de texto é o processo de extração de informações linguísticas do texto de entrada, como transcrição fonética, prosódia e pontuação. A análise de texto pode ser dividida em dois subcomponentes: normalização de texto e conversão de texto em fonema.
Normalização de texto é o processo de conversão de palavras não padronizadas, como números, abreviações, siglas e expressões idiomáticas, em suas formas completas. Por exemplo, “Dr.” torna-se “médico”, “10” torna-se “dez” e “LOL” torna-se “rindo alto”. A normalização de texto pode ser feita usando gramáticas ou léxicos regulares.
Texto para fonema conversão é o processo de atribuição de símbolos fonéticos a cada palavra do texto, com base em sua ortografia e contexto. Por exemplo, “ler” pode ser pronunciado como /riːd/ ou /rɛd/, dependendo do tempo verbal. A conversão de texto em fonema pode ser feita usando regras de letra em som ou análise morfossintática. - Síntese de fala é o processo de geração de sinais de fala a partir da informação linguística produzida pela análise de texto. A síntese de fala pode ser feita usando vários métodos, como abordagens de concatenação, paramétricas ou baseadas em redes neurais.
Concatenação é o método de unir unidades de fala pré-gravadas, como palavras, sílabas ou fonemas, para formar uma fala contínua. A qualidade da concatenação depende do tamanho e da seleção das unidades de fala, bem como das técnicas de suavização utilizadas para reduzir as descontinuidades.
Paramétrico é o método de usar um modelo matemático do trato vocal humano e outras características da voz para gerar fala sintética. Os parâmetros do modelo são derivados da informação linguística e modificados por regras de prosódia. A qualidade da síntese paramétrica depende da precisão e naturalidade do modelo.
Rede neural-based é o método de usar um algoritmo de aprendizado profundo para aprender o mapeamento entre informações linguísticas e sinais de fala a partir de um grande corpus de dados de fala. A rede neural pode gerar fala de alta qualidade e som natural com o mínimo de intervenção humana. No entanto, este método requer muitos recursos computacionais e dados
Quais são os benefícios do Text to Speech?
A tecnologia de conversão de texto em fala oferece uma ampla gama de benefícios, especialmente para a criação de audiolivros. Em primeiro lugar, é elimina a necessidade de estúdios de gravação, engenheiros de som e dubladores caros, tornando o processo de produção significativamente mais econômico. Além disso, o texto para fala permite autores e editores para personalizar seus livros em termos de velocidade de leitura e até mesmo sotaques, abrindo possibilidades para ofertas diversificadas e inclusivas de audiolivros.
Acessibilidade e inclusão são valores importantes para a criação de uma sociedade mais equitativa e diversificada. A tecnologia de conversão de texto em fala (TTS) pode desempenhar um papel vital no aumento da acessibilidade e da inclusão para um público mais amplo, especialmente para audiolivros.
TTS é a tecnologia que converte texto escrito em fala falada, utilizando vozes artificiais ou naturais. A TTS pode disponibilizar audiolivros para pessoas que possam ter dificuldade de leitura ou acesso a conteúdo escrito, como pessoas com deficiência visual, dislexia, TDAH ou outras deficiências cognitivas ou de aprendizagem.
A TTS também pode tornar os audiolivros mais inclusivos para pessoas que falam idiomas diferentes ou têm sotaques diferentes, fornecendo uma variedade de vozes e idiomas para você escolher.
Alguns dos benefícios do TTS para audiolivros são:
- O TTS pode melhorar a compreensão e retenção de informações, fornecendo um reforço auditivo do conteúdo escrito
- O TTS pode aumentar o envolvimento e o prazer com os audiolivros, fornecendo vozes naturais e expressivas que combinam com o tom e o humor do conteúdo
- A TTS pode reduzir o custo e a complexidade da produção de audiolivros, usando soluções automatizadas e escaláveis que não requerem narradores humanos ou estúdios
- A TTS pode expandir a disponibilidade e diversidade de audiolivros, permitindo que autores e editores criem audiolivros para qualquer gênero, tópico ou idioma
TTS é uma ferramenta poderosa que pode tornar os audiolivros mais acessíveis e inclusivos para todos. Ao usar o TTS, os ouvintes de audiolivros podem experimentar a alegria da leitura de uma forma que atenda às suas necessidades e preferências.
O Text to Speech pode ser usado para audiolivros?
Sim, a tecnologia de conversão de texto em fala pode ser usada para a criação de audiolivros. Na verdade, tornou-se cada vez mais popular nos últimos anos devido à sua relação custo-benefício e versatilidade. Com o software de conversão de texto em fala, qualquer conteúdo escrito, incluindo livros, PDFs, páginas da web e arquivos de texto, pode ser facilmente convertido em um arquivo de áudio, como MP3 ou WAV, para uma experiência perfeita de audiolivro.
Como usar o AI Voice Generator para audiolivros
O que é um gerador de voz AI?
Um gerador de voz de IA é um tipo de software de conversão de texto em fala que utiliza inteligência artificial para criar vozes mais realistas e com som natural. Geradores de voz de IA, como VOICEAIR, UberTTS, Speechify ou Lovo oferecem uma variedade de personalizações, incluindo velocidade de leitura, tom e até mesmo a capacidade de escolher um sotaque ou voz específica com base em dialetos regionais. Os geradores de voz de IA permitem maior flexibilidade de voz, resultando em audiolivros mais envolventes.
Quais são os melhores softwares Text to Speech para audiolivros?
Quando se trata de selecionar software de conversão de texto em fala para audiolivros, há uma variedade de opções disponíveis. Algumas das melhores opções de software de texto para fala incluem Polly da Amazon, Text-to-Speech do Google e o recurso de texto para voz integrado da Apple. Essas opções de software permitem que autores e editores convertam facilmente qualquer texto em fala e criem produções de audiolivros de alta qualidade.
UberTTS é um poderoso gerador de texto em fala para audiolivros que combina os recursos de IA de ambos Amazon Polly e Texto do Google para fala juntamente com Azul & IBM vozes.
Alternativamente, você pode usar outros conversores de fala populares, como:
- Leitor Natural: uma solução baseada em nuvem que oferece suporte a vários arquivos e idiomas e permite baixar arquivos de áudio. Possui um nível gratuito e um nível pago com mais recursos.
- Murf: uma ferramenta baseada na web que permite criar narrações realistas para vídeos usando IA. Você pode personalizar a voz, emoção, velocidade e música de fundo. Possui um teste gratuito e um plano de assinatura.
- Amazon Polly: um serviço que fornece vozes realistas usando aprendizado profundo. Você pode usá-lo para criar aplicativos e produtos habilitados para fala, como podcasts, cursos de e-learning e jogos. Possui um modelo de preços pré-pago.
- Jogar.ht: uma plataforma que ajuda você a converter postagens e artigos de seu blog em áudio usando vozes semelhantes às humanas. Você pode incorporar o áudio em seu site ou compartilhá-lo nas redes sociais. Possui um plano gratuito e um plano premium com mais benefícios.
- Leitor de sonhos por voz: um aplicativo que lê qualquer texto em voz alta com vozes naturais. Você pode importar documentos de várias fontes, ajustar a velocidade de leitura e a voz e ouvir offline. Está disponível para dispositivos iOS e Android.
Como o AI Voice pode ajudá-lo a criar audiolivros?
AI Voice oferece uma série de benefícios para a criação de audiolivros, principalmente devido à sua capacidade de gerar uma fala mais natural e realista. Isso pode resultar em uma experiência auditiva mais agradável e envolvente para o público. Além disso, a voz AI permite maior velocidade e eficiência no processo de produção, já que não há necessidade de extensa edição pós-produção.
Usando software de conversão de texto em fala para audiolivros
Quais são os melhores Text to Speech para audiolivros?
Como mencionado anteriormente, alguns dos melhores softwares de texto para fala para audiolivros incluem o Polly da Amazon, o Text-to-Speech do Google e o recurso de texto para voz integrado da Apple. Além disso, há uma variedade de opções de software especializado de conversão de texto em fala disponíveis, como NaturalReader e ReadSpeaker, que oferecem opções de personalização mais avançadas.
Como o software Text to Speech pode ajudá-lo a personalizar seus audiolivros?
O software de conversão de texto em fala permite que autores e editores personalizem facilmente suas produções de audiolivros de várias maneiras. Isso inclui ajustar a velocidade de leitura, o tom e o volume para criar a experiência auditiva ideal. Além disso, o software de conversão de texto em fala permite o uso de diferentes sotaques e dialetos regionais, tornando o audiolivro mais acessível e inclusivo.
O software Text to Speech pode ajudá-lo a criar audiolivros com som natural e sotaques diferentes?
Sim, o software de conversão de texto em fala pode ajudar a criar audiolivros com som natural e sotaques diferentes. Isto é conseguido através da utilização de bancos de dados de voz que incluem uma variedade de dialetos regionais e opções de sotaque. Isso permite maior flexibilidade de voz e uma seleção mais diversificada de audiolivros para o público.
Converter texto em audiolivros
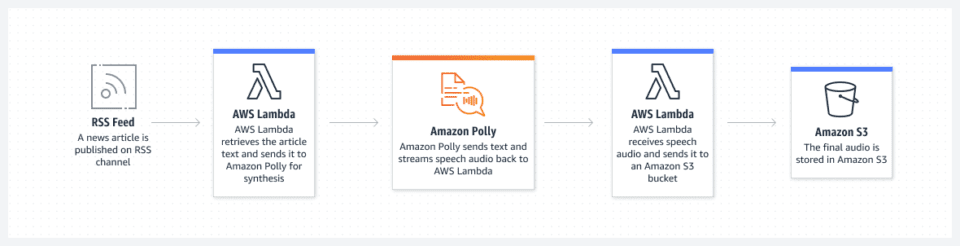 Pin
PinComo converter PDFs em audiolivros usando a tecnologia Text to Speech?
Converter PDFs em audiolivros usando tecnologia de conversão de texto em fala é um processo simples. Em primeiro lugar, selecione seu software de conversão de texto em fala preferido e carregue o documento PDF. O software irá então analisar o texto e convertê-lo em palavras faladas, criando um arquivo de áudio que pode ser baixado em diversos formatos. Isso permite que os indivíduos convertam facilmente o conteúdo escrito em formato de audiolivro para uma experiência de leitura mais versátil.
Quais são as melhores plataformas de audiolivros para usar a tecnologia Text to Speech?
Há uma variedade de plataformas de audiolivros compatíveis com a tecnologia de conversão de texto em fala. Uma das opções mais populares é o Audible, de propriedade da Amazon. A Audible oferece uma variedade de audiolivros compatíveis com software de conversão de texto em fala, permitindo uma experiência auditiva mais personalizável. Outras plataformas populares incluem Apple Books e Google Play Books.
Quais são os benefícios de usar audiolivros com tecnologia Text to Speech?
Há vários benefícios em usar audiolivros com tecnologia de conversão de texto em fala. Em primeiro lugar, permite que os indivíduos convertam facilmente qualquer conteúdo escrito em formato de áudio para maior acessibilidade. Em segundo lugar, a tecnologia de conversão de texto em fala permite maior flexibilidade de voz e pode criar audiolivros com som natural e sotaques diferentes, resultando em uma seleção de audiolivros mais inclusiva e diversificada para o público.
Melhores práticas para usar conversão de texto em fala na produção de audiolivros
Abaixo estão algumas práticas recomendadas possíveis para usar texto em fala na produção de audiolivros:
Escolha uma ferramenta de conversão de texto em fala que ofereça uma variedade de vozes expressivas e com som natural que se adequem ao gênero, ao público e à finalidade do audiolivro. Você também pode personalizar os recursos de voz, como tom, tom, velocidade e volume, para combinar com o clima e a emoção do texto.
Converta o conteúdo escrito em formato de áudio usando um sintetizador de voz. Isso lhe dará uma ideia de como o texto soa e identificará quaisquer erros, inconsistências ou ambiguidades que precisam ser corrigidas ou esclarecidas.3. Você também pode usar o áudio como referência para sua própria narração ou edição.
Edite o conteúdo de áudio para melhorar sua qualidade e clareza. Você pode usar um software de edição de áudio para aparar, cortar, unir, mesclar ou ajustar os segmentos de áudio. Você também pode adicionar efeitos sonoros, música ou ruído de fundo para criar uma experiência auditiva mais envolvente e realista.
Teste o conteúdo de áudio com diferentes dispositivos, plataformas e ouvintes. Você pode usar diferentes fones de ouvido, alto-falantes ou reprodutores de mídia para verificar a qualidade do som e a compatibilidade do conteúdo de áudio. Você também pode pedir feedback de potenciais ouvintes ou especialistas para avaliar a eficácia e o apelo do conteúdo de áudio.
Combinando texto para fala e narração humana para audiolivros
Combinando texto em fala e narração humana para audiolivros é um tópico que explora como usar inteligência artificial para criar audiolivros de alta qualidade a partir de arquivos de texto. É uma tecnologia que pode tornar a produção de audiolivros mais acessível, acessível e diversificada para autores e editores. Alguns exemplos de serviços que oferecem esta tecnologia são Narração digital do Apple Books e Audiolivros com narração automática do Google Play Livros.
Esses serviços utilizam síntese avançada de fala e processamento de linguagem natural para gerar vozes realistas e expressivas que podem narrar diferentes gêneros de livros. Eles também permitem que autores e editores retenham os direitos de seus audiolivros e os distribuam por meio de diversas plataformas.
No entanto, estes serviços também enfrentam alguns desafios e limitações, como garantir a precisão, qualidade e consistência da narração, respeitar as escolhas e preferências criativas dos autores e narradores, e competir com o mercado de audiolivros narrados por humanos que ainda valoriza a magia e arte das vozes humanas.
Compreendendo a abordagem híbrida: Integrando TTS e narração humana na produção de audiolivros.
A abordagem híbrida: Integrando TTS e narração humana na produção de audiolivros é um artigo de pesquisa que propõe um novo método para combinar dois tipos de síntese de texto para fala (TTS): TTS concatenativo (CTTS) e TTS estatístico (STTS). O CTTS utiliza segmentos naturais de fala de um banco de dados gravado, enquanto o STTS gera recursos de fala a partir de um modelo estatístico.
O artigo argumenta que o CTTS pode produzir fala natural e de alta qualidade, mas pode sofrer descontinuidades e limitações de dados. Por outro lado, o STTS pode produzir uma fala suave e consistente, mas pode soar abafada e pouco natural.
O artigo sugere que, usando um algoritmo de caminho dinâmico híbrido, é possível construir uma representação de enunciado que entrelaça segmentos naturais e segmentos gerados por modelo, aproveitando assim as vantagens de ambas as abordagens. O artigo relata testes de audição que demonstram a validade e eficácia do método proposto.
Benefícios de usar o TTS como ferramenta de redação e revisão para narradores humanos
Usar o TTS como ferramenta de redação e revisão para narradores humanos pode trazer vários benefícios, como:
- Pode ajudar os narradores humanos a preparar e praticar os seus guiões antes da gravação, permitindo-lhes ouvir como o texto soa e identificar quaisquer erros, inconsistências ou ambiguidades que precisam de ser corrigidos ou esclarecidos.
- Pode ajudar os narradores humanos a melhorar o seu desempenho e entrega, fornecendo-lhes feedback sobre a sua pronúncia, entonação, ritmo e expressão, e sugerindo formas de melhorar a sua qualidade de voz e emoção.
- Pode ajudar os narradores humanos a poupar tempo e dinheiro, reduzindo a necessidade de múltiplas gravações e edições e permitindo-lhes trabalhar remotamente e em colaboração com outros narradores, editores e produtores.
- Pode ajudar narradores humanos a criar audiolivros mais diversos e inclusivos, permitindo-lhes experimentar diferentes vozes, sotaques, idiomas e estilos que se adequam ao gênero, público e propósito do audiolivro.
Alcançando uma combinação perfeita: estratégias para combinar TTS e narração humana de forma eficaz
Algumas estratégias possíveis para combinar efetivamente o TTS e a narração humana são:
- Use o TTS como uma ferramenta de redação e revisão para narradores humanos, permitindo-lhes ouvir como o texto soa e identificar quaisquer erros, inconsistências ou ambiguidades que precisam ser corrigidos ou esclarecidos1. O TTS também pode fornecer feedback sobre pronúncia, entonação, ritmo e expressão, além de sugerir maneiras de melhorar a qualidade da voz e a emoção..
- Use o TTS como base para o conteúdo de áudio, que pode então ser aprimorado com a adição de dubladores humanos. Os dubladores humanos podem trazer um nível de autenticidade e personalização ao conteúdo de áudio que não pode ser alcançado apenas através do TTS. Eles podem interpretar roteiros e transmitir tons e nuances emocionais que são difíceis de capturar com o TTS. Os dubladores humanos também podem ajustar sua apresentação com base no feedback do público, o que melhora ainda mais a personalização e a eficácia do conteúdo de áudio..
- Use o TTS para gerar uma trilha de narração básica para conteúdo multimídia, que pode então ser personalizada e aprimorada com a adição de dubladores humanos em vários idiomas. Essa abordagem agiliza o processo de localização e reduz os custos de produção, ao mesmo tempo que fornece conteúdo de áudio personalizado e de alta qualidade para públicos globais.
Exemplos de audiolivros de sucesso que empregam a abordagem híbrida
Vejamos alguns exemplos possíveis de audiolivros de ficção científica que usam a abordagem híbrida:
- Atualizar alma por Ezra Claytan Daniels, narrado por Marcia Gay Harden, Wendell Pierce e outros. Esta é uma adaptação em áudio de uma história em quadrinhos que usa uma mistura de segmentos de fala natural e segmentos gerados por modelos para criar uma narração realista e expressiva. A história segue um casal de idosos que passa por um procedimento experimental para rejuvenescer o corpo e a mente, mas acaba com resultados horríveis..
- Quão alto vamos no escuro de Sequoia Nagamatsu, narrado por um elenco completo. Este é um romance de ficção científica que usa um elenco completo de dubladores para dar vida a múltiplas histórias, personagens e lugares que se interconectam de maneiras complexas e satisfatórias. A história abrange séculos e continentes, explorando como a humanidade lida com uma pandemia que faz com que as pessoas emitam luz quando morrem.
- Gideão, o Nono por Tamsyn Muir, narrado por Moira Quirk. Este é um romance de fantasia de ficção científica que usa um único dublador para oferecer uma performance impressionante que captura o humor, o terror e o cerne da história. A história segue Gideon, uma espadachim que acompanha sua amante necromante até um palácio assombrado onde eles devem competir com outros necromantes por um prêmio.
A abordagem híbrida aprimora esses audiolivros, criando uma experiência auditiva mais envolvente e envolvente para o público. Ao combinar segmentos de fala natural e segmentos gerados por modelo, a abordagem híbrida pode produzir uma fala natural e de alta qualidade que corresponda ao tom e ao clima da história.
Ao utilizar um elenco completo de dubladores, a abordagem híbrida pode criar um conteúdo de áudio diversificado e inclusivo que reflete a variedade de personagens e perspectivas da história. Ao usar um único dublador, a abordagem híbrida pode criar um conteúdo de áudio personalizado e com nuances emocionais que transmite a personalidade e a voz do narrador.
A abordagem híbrida também pode tornar os audiolivros mais acessíveis e adaptáveis a diferentes idiomas, plataformas e dispositivos.
Como será o futuro dos audiolivros com IA?
Como a IA pode melhorar os audiolivros no futuro?
A IA tem potencial para melhorar significativamente a experiência do audiolivro de várias maneiras. Em primeiro lugar, a IA pode ajudar a criar vozes e sotaques ainda mais naturais, resultando numa experiência auditiva mais envolvente e realista.
Além disso, a IA tem a capacidade de otimizar dinamicamente os audiolivros com base nas preferências do ouvinte, como ajustar a velocidade ou o tom de leitura.
Por fim, a IA tem a capacidade de personalizar a experiência do audiolivro, criando produções exclusivas adaptadas a ouvintes individuais com base em seu histórico e preferências de audição.
Quais novos recursos podem ser esperados em 2023?
É difícil prever exatamente quais novos recursos serão lançados em 2023, mas pode-se presumir que a IA continuará a desempenhar um papel significativo na evolução dos audiolivros. Novos recursos podem incluir bancos de dados de voz aprimorados, maior flexibilidade de voz e ferramentas aprimoradas de edição de pós-produção para experiências auditivas ainda mais personalizadas.
Os dubladores serão substituídos por vozes geradas por IA?
Embora as vozes geradas por IA estejam se tornando cada vez mais realistas, é improvável que substituam completamente os dubladores num futuro próximo. Os dubladores ainda oferecem uma série de benefícios, incluindo maior profundidade emocional e versatilidade em suas performances.
No entanto, as vozes geradas por IA continuarão a desempenhar um papel importante na produção de audiolivros, especialmente com conteúdos mais técnicos ou educacionais, onde a fala com som natural é uma prioridade sobre características de voz únicas.
Perguntas frequentes (FAQ)
O que é conversão de texto em fala?
Text-to-speech é uma tecnologia que permite a conversão de texto escrito em palavras faladas.
Como funciona a conversão de texto em fala para audiolivros?
A tecnologia de conversão de texto em fala pode ser usada para transformar o texto de um e-book ou PDF em um arquivo de áudio que pode ser reproduzido como um audiolivro. Isto pode proporcionar uma experiência auditiva acessível para aqueles que preferem ouvir a leitura ou que têm deficiência visual.
Quais são os benefícios de usar a conversão de texto em fala para audiolivros?
A conversão de texto em fala pode oferecer uma maneira mais rápida e conveniente de ouvir audiolivros. Permite maior personalização, pois os ouvintes podem escolher a voz e a velocidade da narração, podendo até pausar, retroceder ou pular seções conforme necessário.
Como posso usar a tecnologia de conversão de texto em fala para criar meus próprios audiolivros?
Existem várias ferramentas e softwares disponíveis que permitem a fácil conversão de texto em fala. Alguns podem exigir uma taxa ou assinatura, enquanto outros podem ser gratuitos ou de código aberto.
Qual é a melhor ferramenta de conversão de texto em fala para audiolivros?
Existem muitas ferramentas de conversão de texto em fala disponíveis no mercado, cada uma com seus próprios recursos e benefícios exclusivos. Algumas opções populares incluem VOICEAIR, UberTTS, Speechify, NaturalReader e Balabolka.
Como posso escolher a melhor voz de conversão de texto em fala?
A maioria das ferramentas de conversão de texto em fala oferece uma ampla seleção de vozes para você escolher, desde vozes humanas naturais até geradores avançados de conversão de texto em fala com IA. Você pode selecionar a voz de IA que melhor se adapta às suas preferências e necessidades ou pode escolher entre uma coleção de vozes de IA.
A tecnologia de conversão de texto em fala pode ser usada para converter texto em áudio para outros fins?
Sim, a conversão de texto em fala pode ser usada para transformar texto impresso para diversos fins, como podcasts, apresentações, narração em vídeo, locuções, seja para uso pessoal ou comercial.
Qual é a diferença entre conversão de texto em fala e dublador para audiolivros?
Embora a tecnologia de conversão de texto em fala possa fornecer uma maneira rápida e econômica de criar audiolivros, alguns argumentam que um dublador humano pode fornecer uma experiência auditiva mais envolvente e emocional.
Como a conversão de texto em fala afeta a experiência auditiva de audiolivros?
Como qualquer ferramenta, a conversão de texto em fala pode melhorar ou prejudicar a experiência auditiva dos audiolivros, dependendo da qualidade da voz, da precisão da narração e das preferências do ouvinte.
Quais são algumas dicas para usar a conversão de texto em fala para obter a melhor experiência auditiva?
Algumas dicas para usar a conversão de texto em fala para obter a melhor experiência auditiva incluem selecionar uma ótima ferramenta de conversão de texto em fala, escolher uma voz de alta qualidade e ajustar a velocidade e o tom da fala para atender às suas preferências.


