
Hörbücher erfreuen sich in den letzten Jahren aufgrund ihrer Bequemlichkeit und Kompatibilität mit modernen Lebensstilen immer größerer Beliebtheit. Ob beim täglichen Pendeln oder bei der Hausarbeit: Hörbücher ermöglichen es dem Einzelnen, unterwegs in seine Lieblingsgeschichten einzutauchen.
Die Erstellung eines Hörbuchs erfordert jedoch in der Regel einen erheblichen Zeit- und Geldaufwand. Hier kommt die Text-to-Speech-Technologie ins Spiel, die sowohl Autoren als auch Verlegern eine innovative Lösung bietet.
Was ist Text-to-Speech?
Text to Speech ist eine Technologie, die es ermöglicht, geschriebenen Text in gesprochene Wörter umzuwandeln. Dies wird durch einen Prozess namens Sprachsynthese erreicht, der verschiedene Algorithmen und Sprachdatenbanken nutzt, um realistische, menschenähnliche Sprache zu erzeugen. Die Text-to-Speech-Technologie wurde für eine Vielzahl von Anwendungen eingesetzt, darunter Sprachübersetzung, Barrierefreiheit und jetzt auch die Erstellung von Hörbüchern.
Wie funktioniert Text to Speech?
Beim Text-to-Speech-Verfahren wird geschriebener Text analysiert und in einzelne phonetische Einheiten, sogenannte Phoneme, zerlegt. Diese Phoneme werden dann zu Wörtern, Sätzen und letztendlich dem gesprochenen Text kombiniert. Text-to-Speech-Software nutzt maschinelles Lernen, um die Genauigkeit und Natürlichkeit der synthetisierten Stimme kontinuierlich zu verbessern, was im Laufe der Zeit zu realistischeren KI-Stimmen führt.
Komponenten eines TTS-Systems
Ein TTS-System besteht aus zwei Hauptkomponenten: Textanalyse und Sprachsynthese.
- Textanalyse ist der Prozess des Extrahierens sprachlicher Informationen aus dem Eingabetext, z. B. phonetischer Transkription, Prosodie und Zeichensetzung. Die Textanalyse kann weiter in zwei Unterkomponenten unterteilt werden: Textnormalisierung und Text-zu-Phonem-Konvertierung.
Textnormalisierung ist der Prozess der Umwandlung nicht standardmäßiger Wörter wie Zahlen, Abkürzungen, Akronyme und Redewendungen in ihre vollständige Form. Zum Beispiel „Dr.“ wird zu „Doktor“, aus „10“ wird „zehn“ und aus „LOL“ wird „lautes Lachen“. Die Textnormalisierung kann mithilfe regulärer Grammatiken oder Lexika erfolgen.
Text-zu-Phonem Bei der Konvertierung werden jedem Wort im Text auf der Grundlage seiner Schreibweise und seines Kontexts phonetische Symbole zugewiesen. „read“ kann beispielsweise je nach Zeitform als /riːd/ oder /rɛd/ ausgesprochen werden. Die Text-zu-Phonem-Konvertierung kann mithilfe von Buchstaben-zu-Laut-Regeln oder einer morphosyntaktischen Analyse erfolgen. - Sprachsynthese ist der Prozess der Generierung von Sprachsignalen aus den durch die Textanalyse erzeugten sprachlichen Informationen. Die Sprachsynthese kann mithilfe verschiedener Methoden erfolgen, beispielsweise durch Verkettung, parametrische oder auf neuronalen Netzwerken basierende Ansätze.
Verkettung ist die Methode, vorab aufgezeichnete Spracheinheiten wie Wörter, Silben oder Phoneme zu einer kontinuierlichen Sprache zusammenzufügen. Die Qualität der Verkettung hängt von der Größe und Auswahl der Spracheinheiten sowie den Glättungstechniken zur Reduzierung von Diskontinuitäten ab.
Parametrisch ist die Methode, ein mathematisches Modell des menschlichen Stimmapparats und anderer Stimmmerkmale zu verwenden, um synthetische Sprache zu erzeugen. Die Parameter des Modells werden aus den sprachlichen Informationen abgeleitet und durch Prosodieregeln modifiziert. Die Qualität der parametrischen Synthese hängt von der Genauigkeit und Natürlichkeit des Modells ab.
Neurales Netzwerk-basiert ist die Methode, einen Deep-Learning-Algorithmus zu verwenden, um die Zuordnung zwischen sprachlichen Informationen und Sprachsignalen aus einem großen Korpus von Sprachdaten zu lernen. Das neuronale Netzwerk kann mit minimalem menschlichen Eingriff qualitativ hochwertige und natürlich klingende Sprache erzeugen. Diese Methode erfordert jedoch viele Rechenressourcen und Daten
Welche Vorteile bietet Text to Speech?
Die Text-to-Speech-Technologie bietet zahlreiche Vorteile, insbesondere für die Erstellung von Hörbüchern. Erstens, es Dadurch entfallen teure Aufnahmestudios, Tontechniker und Synchronsprecher, was den Produktionsprozess deutlich kosteneffizienter macht. Darüber hinaus ist Text-to-Speech möglich Autoren und Verlegern die Möglichkeit, ihre Bücher individuell anzupassen in Bezug auf Lesegeschwindigkeit und gleichmäßige Akzente, was Möglichkeiten für vielfältige und integrative Hörbuchangebote eröffnet.
Zugänglichkeit und Inklusivität sind wichtige Werte für die Schaffung einer gerechteren und vielfältigeren Gesellschaft. Die Text-to-Speech-Technologie (TTS) kann eine entscheidende Rolle bei der Verbesserung der Zugänglichkeit und Inklusivität für ein breiteres Publikum spielen, insbesondere bei Hörbüchern.
TTS ist die Technologie, die geschriebenen Text mithilfe künstlicher oder natürlicher Stimmen in gesprochene Sprache umwandelt. TTS kann Hörbücher für Personen verfügbar machen, die möglicherweise Schwierigkeiten beim Lesen oder beim Zugriff auf geschriebene Inhalte haben, beispielsweise Personen mit Sehbehinderungen, Legasthenie, ADHS oder anderen kognitiven oder Lernbehinderungen.
TTS kann Hörbücher auch für Menschen, die unterschiedliche Sprachen sprechen oder unterschiedliche Akzente haben, integrativer gestalten, indem es eine Vielzahl von Stimmen und Sprachen zur Auswahl bietet.
Zu den Vorteilen von TTS für Hörbücher gehören:
- TTS kann das Verständnis und die Speicherung von Informationen verbessern, indem es eine akustische Verstärkung des geschriebenen Inhalts bietet
- TTS kann das Engagement und die Freude an Hörbüchern steigern, indem es natürliche und ausdrucksstarke Stimmen bereitstellt, die zum Ton und zur Stimmung des Inhalts passen
- TTS kann die Kosten und die Komplexität der Produktion von Hörbüchern reduzieren, indem es automatisierte und skalierbare Lösungen verwendet, die keine menschlichen Erzähler oder Studios erfordern
- TTS kann die Verfügbarkeit und Vielfalt von Hörbüchern erweitern, indem es Autoren und Verlegern ermöglicht, Hörbücher für jedes Genre, Thema und jede Sprache zu erstellen
TTS ist ein leistungsstarkes Tool, das Hörbücher für alle zugänglicher und integrativer machen kann. Durch die Nutzung von TTS können Hörbuchhörer die Freude am Lesen auf eine Weise erleben, die ihren Bedürfnissen und Vorlieben entspricht.
Kann Text to Speech für Hörbücher verwendet werden?
Ja, die Text-to-Speech-Technologie kann für die Erstellung von Hörbüchern verwendet werden. Tatsächlich ist es in den letzten Jahren aufgrund seiner Kosteneffizienz und Vielseitigkeit immer beliebter geworden. Mit Text-to-Speech-Software können alle geschriebenen Inhalte, einschließlich Bücher, PDFs, Webseiten und Textdateien, problemlos in eine Audiodatei wie MP3 oder WAV konvertiert werden, um ein nahtloses Hörbucherlebnis zu ermöglichen.
So verwenden Sie den AI Voice Generator für Hörbücher
Was ist ein KI-Sprachgenerator?
Ein KI-Sprachgenerator ist eine Art Text-to-Speech-Software, die künstliche Intelligenz nutzt, um realistischere und natürlicher klingende Stimmen zu erzeugen. KI-Sprachgeneratoren, wie z VOICEAIR, UberTTS, Speechify oder Lovo bieten eine Reihe von Anpassungen, darunter Lesegeschwindigkeit, Tonhöhe und sogar die Möglichkeit, einen bestimmten Akzent oder eine bestimmte Stimme basierend auf regionalen Dialekten auszuwählen. KI-Sprachgeneratoren ermöglichen eine verbesserte Sprachflexibilität, was zu ansprechenderen Hörbüchern führt.
Was ist die beste Text-to-Speech-Software für Hörbücher?
Bei der Auswahl von Text-to-Speech-Software für Hörbücher stehen verschiedene Optionen zur Verfügung. Zu den besten Text-to-Speech-Softwareoptionen gehören Polly von Amazon, Text-to-Speech von Google und die integrierte Text-to-Voice-Funktion von Apple. Diese Softwareoptionen ermöglichen es Autoren und Verlegern, beliebige Texte problemlos in Sprache umzuwandeln und hochwertige Hörbuchproduktionen zu erstellen.
UberTTS ist einer der leistungsstarken Text-to-Speech-Generatoren für Hörbücher vereint die KI-Fähigkeiten von beide Amazon Polly und Google Text-to-Speech zusammen mit Azurblau & IBM Stimmen.
Alternativ können Sie auch andere beliebte Sprachkonverter verwenden wie:
- NaturalReader: Eine cloudbasierte Lösung, die eine Reihe von Dateien und Sprachen unterstützt und Ihnen das Herunterladen von Audiodateien ermöglicht. Es gibt eine kostenlose und eine kostenpflichtige Stufe mit mehr Funktionen.
- Murf: Ein webbasiertes Tool, mit dem Sie mithilfe von KI realistische Voice-Overs für Videos erstellen können. Sie können Stimme, Emotionen, Geschwindigkeit und Hintergrundmusik anpassen. Es gibt eine kostenlose Testversion und ein Abonnement.
- Amazon Polly: Ein Dienst, der mithilfe von Deep Learning lebensechte Stimmen bereitstellt. Sie können damit sprachgestützte Anwendungen und Produkte wie Podcasts, E-Learning-Kurse und Spiele erstellen. Es gibt ein Pay-as-you-go-Preismodell.
- Play.ht: Eine Plattform, die Ihnen hilft, Ihre Blogbeiträge und Artikel mit menschenähnlichen Stimmen in Audio umzuwandeln. Sie können das Audio auf Ihrer Website einbetten oder in sozialen Medien teilen. Es gibt einen kostenlosen Plan und einen Premium-Plan mit mehr Vorteilen.
- Sprachtraumleser: Eine App, die jeden Text mit natürlich klingenden Stimmen vorliest. Sie können Dokumente aus verschiedenen Quellen importieren, die Lesegeschwindigkeit und die Stimme anpassen und offline anhören. Es ist für iOS- und Android-Geräte verfügbar.
Wie kann AI Voice Ihnen bei der Erstellung von Hörbüchern helfen?
AI Voice bietet eine Reihe von Vorteilen für die Erstellung von Hörbüchern, vor allem aufgrund seiner Fähigkeit, natürlichere und realistischer klingende Sprache zu erzeugen. Dies kann zu einem angenehmeren und intensiveren Hörerlebnis für das Publikum führen. Darüber hinaus ermöglicht AI Voice eine höhere Geschwindigkeit und Effizienz im Produktionsprozess, da keine aufwändige Nachbearbeitung erforderlich ist.
Verwendung von Text-to-Speech-Software für Hörbücher
Welches sind die besten Text-to-Speech-Lösungen für Hörbücher?
Wie bereits erwähnt, gehören zu den besten Text-to-Speech-Programmen für Hörbücher Amazons Polly, Googles Text-to-Speech und die integrierte Text-to-Voice-Funktion von Apple. Darüber hinaus stehen eine Reihe spezieller Text-zu-Sprache-Softwareoptionen zur Verfügung, beispielsweise NaturalReader und ReadSpeaker, die erweiterte Anpassungsoptionen bieten.
Wie kann Ihnen die Text-to-Speech-Software dabei helfen, Ihre Hörbücher individuell anzupassen?
Text-to-Speech-Software ermöglicht es Autoren und Verlegern, ihre Hörbuchproduktionen auf vielfältige Weise einfach anzupassen. Dazu gehört die Anpassung der Lesegeschwindigkeit, Tonhöhe und Lautstärke, um ein optimales Hörerlebnis zu schaffen. Darüber hinaus ermöglicht Text-to-Speech-Software die Verwendung verschiedener Akzente und regionaler Dialekte, wodurch das Hörbuch zugänglicher und integrativer wird.
Kann Ihnen die Text-to-Speech-Software dabei helfen, natürlich klingende Hörbücher mit unterschiedlichen Akzenten zu erstellen?
Ja, Text-to-Speech-Software kann dabei helfen, natürlich klingende Hörbücher mit unterschiedlichen Akzenten zu erstellen. Dies wird durch die Nutzung von Sprachdatenbanken erreicht, die eine Reihe regionaler Dialekte und Akzentoptionen umfassen. Dies ermöglicht eine größere Sprachflexibilität und eine vielfältigere Auswahl an Hörbüchern für das Publikum.
Konvertieren Sie Text in Hörbücher
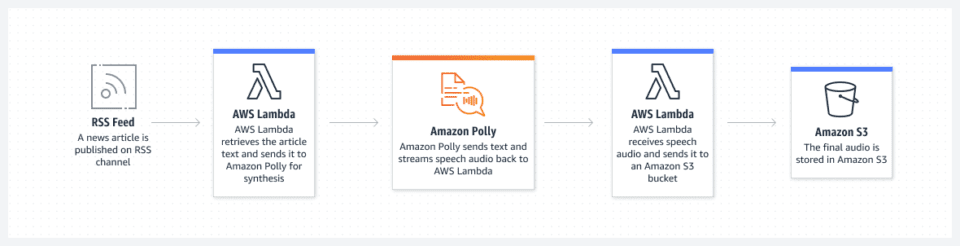 Pin
PinWie konvertiert man PDFs mithilfe der Text-to-Speech-Technologie in Hörbücher?
Das Konvertieren von PDFs in Hörbücher mithilfe der Text-to-Speech-Technologie ist ein einfacher Vorgang. Wählen Sie zunächst Ihre bevorzugte Text-to-Speech-Software aus und laden Sie das PDF-Dokument hoch. Anschließend analysiert die Software den Text, wandelt ihn in gesprochene Wörter um und erstellt so eine Audiodatei, die in verschiedenen Formaten heruntergeladen werden kann. Dies ermöglicht es Einzelpersonen, geschriebene Inhalte einfach in ein Hörbuchformat umzuwandeln, um ein vielseitigeres Leseerlebnis zu ermöglichen.
Was sind die besten Hörbuchplattformen für die Verwendung der Text-to-Speech-Technologie?
Es gibt eine Vielzahl von Hörbuchplattformen, die mit der Text-to-Speech-Technologie kompatibel sind. Eine der beliebtesten Optionen ist das Amazon-eigene Audible. Audible bietet eine Reihe von Hörbüchern an, die mit Text-to-Speech-Software kompatibel sind und ein individuelleres Hörerlebnis ermöglichen. Weitere beliebte Plattformen sind Apple Books und Google Play Books.
Welche Vorteile bietet die Verwendung von Hörbüchern mit Text-to-Speech-Technologie?
Die Verwendung von Hörbüchern mit Text-to-Speech-Technologie bietet zahlreiche Vorteile. Erstens ermöglicht es Einzelpersonen, jeden geschriebenen Inhalt für eine bessere Zugänglichkeit einfach in ein Audioformat umzuwandeln. Zweitens ermöglicht die Text-to-Speech-Technologie eine größere Sprachflexibilität und kann natürlich klingende Hörbücher mit unterschiedlichen Akzenten erstellen, was zu einer umfassenderen und vielfältigeren Auswahl an Hörbüchern für das Publikum führt.
Best Practices für die Verwendung von Text-to-Speech in der Hörbuchproduktion
Nachfolgend sind einige mögliche Best Practices für die Verwendung von Text-to-Speech bei der Hörbuchproduktion aufgeführt:
Wählen Sie ein Text-to-Speech-Tool, das eine Vielzahl natürlich klingender und ausdrucksstarker Stimmen bietet, die zum Genre, der Zielgruppe und dem Zweck des Hörbuchs passen. Sie können auch die Sprachfunktionen wie Ton, Tonhöhe, Geschwindigkeit und Lautstärke anpassen, um sie an die Stimmung und Emotion des Textes anzupassen.
Wandeln Sie den geschriebenen Inhalt mithilfe eines Sprachsynthesizers in ein Audioformat um. Dadurch erhalten Sie eine Vorstellung davon, wie der Text klingt, und erkennen etwaige Fehler, Inkonsistenzen oder Unklarheiten, die korrigiert oder geklärt werden müssen3. Sie können das Audio auch als Referenz für Ihre eigene Erzählung oder Bearbeitung verwenden.
Bearbeiten Sie den Audioinhalt, um dessen Qualität und Klarheit zu verbessern. Mit einer Audiobearbeitungssoftware können Sie die Audiosegmente zuschneiden, schneiden, zusammenfügen, zusammenführen oder anpassen. Sie können auch Soundeffekte, Musik oder Hintergrundgeräusche hinzufügen, um ein noch intensiveres und realistischeres Hörerlebnis zu schaffen.
Testen Sie den Audioinhalt mit verschiedenen Geräten, Plattformen und Hörern. Sie können verschiedene Kopfhörer, Lautsprecher oder Mediaplayer verwenden, um die Klangqualität und Kompatibilität der Audioinhalte zu überprüfen. Sie können auch potenzielle Zuhörer oder Experten um Feedback bitten, um die Wirksamkeit und Attraktivität des Audioinhalts zu bewerten.
Kombination von Text-to-Speech und menschlicher Erzählung für Hörbücher
Die Kombination von Text-to-Speech und menschlicher Erzählung für Hörbücher ist ein Thema, das untersucht, wie man mithilfe künstlicher Intelligenz hochwertige Hörbücher aus Textdateien erstellen kann. Es handelt sich um eine Technologie, die die Produktion von Hörbüchern für Autoren und Verleger zugänglicher, erschwinglicher und vielfältiger machen kann. Einige Beispiele für Dienste, die diese Technologie anbieten, sind: Digitale Erzählung von Apple Books und Automatisch vorgelesene Hörbücher von Google Play Books.
Diese Dienste nutzen fortschrittliche Sprachsynthese und Verarbeitung natürlicher Sprache, um realistische und ausdrucksstarke Stimmen zu erzeugen, die verschiedene Buchgenres erzählen können. Sie ermöglichen es Autoren und Verlegern außerdem, die Rechte an ihren Hörbüchern zu behalten und diese über verschiedene Plattformen zu vertreiben.
Allerdings stehen diese Dienste auch vor einigen Herausforderungen und Einschränkungen, wie z. B. der Gewährleistung der Genauigkeit, Qualität und Konsistenz der Erzählung, der Berücksichtigung der kreativen Entscheidungen und Vorlieben der Autoren und Erzähler und dem Wettbewerb mit dem Markt für von Menschen erzählte Hörbücher, der immer noch Wert auf Magie legt und Kunstfertigkeit menschlicher Stimmen.
Den hybriden Ansatz verstehen: TTS und menschliche Erzählung in die Hörbuchproduktion integrieren.
Der hybride Ansatz: „Integration von TTS und menschlicher Erzählung in die Hörbuchproduktion“ ist ein Forschungsbericht, der eine neuartige Methode zur Kombination zweier Arten der Text-to-Speech-Synthese (TTS) vorschlägt: konkatenatives TTS (CTTS) und statistisches TTS (STTS). CTTS verwendet natürliche Sprachsegmente aus einer aufgezeichneten Datenbank, während STTS Sprachmerkmale aus einem statistischen Modell generiert.
In dem Artikel wird argumentiert, dass CTTS eine natürliche und qualitativ hochwertige Sprache erzeugen kann, jedoch unter Diskontinuitäten und Datenbeschränkungen leiden kann. Andererseits kann STTS eine flüssige und gleichmäßige Sprache erzeugen, die jedoch möglicherweise gedämpft und unnatürlich klingt.
Der Artikel schlägt vor, dass es durch die Verwendung eines hybriden dynamischen Pfadalgorithmus möglich ist, eine Äußerungsdarstellung zu konstruieren, die natürliche Segmente und modellgenerierte Segmente miteinander verwebt und so die Vorteile beider Ansätze nutzt. Das Papier berichtet über Hörtests, die die Gültigkeit und Wirksamkeit der vorgeschlagenen Methode belegen.
Vorteile der Verwendung von TTS als Entwurfs- und Korrekturwerkzeug für menschliche Erzähler
Die Verwendung von TTS als Entwurfs- und Korrekturwerkzeug für menschliche Erzähler kann mehrere Vorteile haben, wie zum Beispiel:
- Es kann menschlichen Erzählern helfen, ihre Skripte vor der Aufnahme vorzubereiten und zu üben, indem es ihnen ermöglicht, zuzuhören, wie der Text klingt, und etwaige Fehler, Inkonsistenzen oder Unklarheiten zu erkennen, die korrigiert oder geklärt werden müssen.
- Es kann menschlichen Erzählern helfen, ihre Leistung und Darbietung zu verbessern, indem es ihnen Feedback zu ihrer Aussprache, Intonation, ihrem Tempo und ihrem Ausdruck gibt und Möglichkeiten zur Verbesserung ihrer Stimmqualität und Emotion vorschlägt.
- Es kann menschlichen Erzählern helfen, Zeit und Geld zu sparen, indem es die Notwendigkeit mehrerer Aufnahmen und Bearbeitungen reduziert und es ihnen ermöglicht, aus der Ferne und gemeinsam mit anderen Erzählern, Redakteuren und Produzenten zusammenzuarbeiten.
- Es kann menschlichen Erzählern helfen, vielfältigere und umfassendere Hörbücher zu erstellen, indem es ihnen ermöglicht, mit verschiedenen Stimmen, Akzenten, Sprachen und Stilen zu experimentieren, die zum Genre, Publikum und Zweck des Hörbuchs passen
Eine nahtlose Mischung erreichen: Strategien zur effektiven Kombination von TTS und menschlicher Erzählung
Einige mögliche Strategien, um TTS und menschliche Erzählung effektiv zu kombinieren, sind:
- Nutzen Sie TTS als Entwurfs- und Korrekturwerkzeug für menschliche Erzähler, indem Sie ihnen ermöglichen, zuzuhören, wie der Text klingt, und etwaige Fehler, Inkonsistenzen oder Unklarheiten zu erkennen, die korrigiert oder geklärt werden müssen1. TTS kann auch Feedback zu Aussprache, Intonation, Tempo und Ausdruck geben und Möglichkeiten zur Verbesserung der Stimmqualität und Emotion vorschlagen.
- Verwenden Sie TTS als Grundlage für Audioinhalte, die dann durch die Hinzufügung menschlicher Synchronsprecher erweitert werden können. Menschliche Synchronsprecher können Audioinhalten ein Maß an Authentizität und Personalisierung verleihen, das mit TTS allein nicht erreicht werden kann. Sie können Drehbücher interpretieren und emotionale Töne und Nuancen vermitteln, die mit TTS schwer einzufangen sind. Menschliche Synchronsprecher können ihre Darbietung auch basierend auf dem Feedback des Publikums anpassen, was die Personalisierung und Effektivität des Audioinhalts weiter verbessert.
- Verwenden Sie TTS, um eine grundlegende Erzählspur für Multimedia-Inhalte zu erstellen, die dann durch die Hinzufügung menschlicher Synchronsprecher in verschiedenen Sprachen angepasst und erweitert werden kann. Dieser Ansatz rationalisiert den Lokalisierungsprozess und senkt die Produktionskosten, während gleichzeitig hochwertige, personalisierte Audioinhalte an ein globales Publikum geliefert werden.
Beispiele erfolgreicher Hörbücher, die den Hybrid-Ansatz nutzen
Schauen wir uns einige mögliche Beispiele für Science-Fiction-Hörbücher an, die den Hybrid-Ansatz verwenden:
- Verbessere die Seele von Ezra Claytan Daniels, erzählt von Marcia Gay Harden, Wendell Pierce und anderen. Hierbei handelt es sich um eine Audioadaption einer Graphic Novel, die eine Mischung aus natürlichen Sprachsegmenten und modellgenerierten Segmenten verwendet, um eine realistische und ausdrucksstarke Erzählung zu schaffen. Die Geschichte handelt von einem älteren Ehepaar, das sich einem experimentellen Verfahren zur Verjüngung von Körper und Geist unterzieht, das jedoch mit erschreckenden Ergebnissen endet.
- Wie hoch wir im Dunkeln gehen von Sequoia Nagamatsu, erzählt von einer kompletten Besetzung. Dies ist ein Science-Fiction-Roman, der mit einer kompletten Besetzung von Synchronsprechern mehrere Geschichten, Charaktere und Orte zum Leben erweckt, die auf komplexe und befriedigende Weise miteinander verbunden sind. Die Geschichte erstreckt sich über Jahrhunderte und Kontinente und untersucht, wie die Menschheit mit einer Pandemie umgeht, die dazu führt, dass Menschen nach ihrem Tod Licht aussenden.
- Gideon der Neunte von Tamsyn Muir, erzählt von Moira Quirk. Dies ist ein Science-Fiction-Fantasy-Roman, der mit einem einzigen Synchronsprecher eine atemberaubende Leistung liefert, die den Humor, den Horror und den Kern der Geschichte einfängt. Die Geschichte dreht sich um Gideon, eine Schwertkämpferin, die ihre Nekromantin-Herrin zu einem verwunschenen Palast begleitet, wo sie mit anderen Nekromanten um einen Preis konkurrieren müssen.
Der hybride Ansatz wertet diese Hörbücher auf, indem er dem Publikum ein noch intensiveres und ansprechenderes Hörerlebnis bietet. Durch die Kombination natürlicher Sprachsegmente und modellgenerierter Segmente kann der Hybridansatz eine natürliche und qualitativ hochwertige Sprache erzeugen, die dem Ton und der Stimmung der Geschichte entspricht.
Durch den Einsatz einer vollständigen Besetzung von Synchronsprechern kann der hybride Ansatz vielfältige und umfassende Audioinhalte schaffen, die die Vielfalt der Charaktere und Perspektiven in der Geschichte widerspiegeln. Durch die Verwendung eines einzigen Synchronsprechers kann der hybride Ansatz einen personalisierten und emotional nuancierten Audioinhalt erstellen, der die Persönlichkeit und Stimme des Erzählers vermittelt.
Der hybride Ansatz kann die Hörbücher auch zugänglicher und an verschiedene Sprachen, Plattformen und Geräte anpassbar machen.
Wie sieht die Zukunft von Hörbüchern mit KI aus?
Wie kann KI künftig Hörbücher verbessern?
KI hat das Potenzial, das Hörbucherlebnis auf vielfältige Weise deutlich zu verbessern. Erstens kann KI dazu beitragen, noch natürlicher klingende Stimmen und Akzente zu erzeugen, was zu einem intensiveren und realistischeren Hörerlebnis führt.
Darüber hinaus ist KI in der Lage, Hörbücher basierend auf den Vorlieben des Hörers dynamisch zu optimieren, beispielsweise durch Anpassung der Lesegeschwindigkeit oder des Tons.
Schließlich ist die KI in der Lage, das Hörbucherlebnis zu personalisieren und einzigartige Produktionen zu erstellen, die auf den einzelnen Hörer basierend auf seiner Hörgeschichte und seinen Vorlieben zugeschnitten sind.
Welche Neuerungen sind im Jahr 2023 zu erwarten?
Es ist schwierig, genau vorherzusagen, welche neuen Features im Jahr 2023 erscheinen werden, aber es ist davon auszugehen, dass KI weiterhin eine bedeutende Rolle in der Entwicklung von Hörbüchern spielen wird. Zu den neuen Funktionen gehören möglicherweise verbesserte Sprachdatenbanken, größere Sprachflexibilität und verbesserte Bearbeitungstools für die Nachbearbeitung für noch individuellere und personalisiertere Hörerlebnisse.
Werden Synchronsprecher durch KI-generierte Stimmen ersetzt?
Obwohl KI-generierte Stimmen immer realistischer werden, ist es unwahrscheinlich, dass sie Synchronsprecher in naher Zukunft vollständig ersetzen werden. Synchronsprecher bieten nach wie vor eine Reihe von Vorteilen, darunter eine größere emotionale Tiefe und Vielseitigkeit bei ihren Darbietungen.
KI-generierte Stimmen werden jedoch weiterhin eine wichtige Rolle bei der Produktion von Hörbüchern spielen, insbesondere bei eher technischen oder pädagogischen Inhalten, bei denen natürlich klingende Sprache Vorrang vor einzigartigen Stimmeigenschaften hat.
Häufig gestellte Fragen (FAQs)
Was ist Text-to-Speech?
Text-to-Speech ist eine Technologie, die die Umwandlung von geschriebenem Text in gesprochene Wörter ermöglicht.
Wie funktioniert Text-to-Speech bei Hörbüchern?
Mithilfe der Text-to-Speech-Technologie kann Text aus einem E-Book oder PDF in eine Audiodatei umgewandelt werden, die als Hörbuch abgespielt werden kann. Dies kann ein zugängliches Hörerlebnis für diejenigen bieten, die lieber zuhören als lesen oder Sehbehinderungen haben.
Welche Vorteile bietet die Verwendung von Text-to-Speech für Hörbücher?
Text-to-Speech bietet eine schnellere und bequemere Möglichkeit, Hörbücher anzuhören. Es ermöglicht eine größere Individualisierung, da die Zuhörer die Stimme und Geschwindigkeit des Erzähltexts wählen und je nach Bedarf sogar Abschnitte anhalten, zurückspulen oder überspringen können.
Wie kann ich mithilfe der Text-to-Speech-Technologie meine eigenen Hörbücher erstellen?
Es stehen verschiedene Tools und Software zur Verfügung, die eine einfache Umwandlung von Text in Sprache ermöglichen. Für einige ist möglicherweise eine Gebühr oder ein Abonnement erforderlich, während andere kostenlos oder Open Source sein können.
Was ist das beste Text-to-Speech-Tool für Hörbücher?
Es gibt viele Text-to-Speech-Tools auf dem Markt, jedes mit seinen eigenen einzigartigen Funktionen und Vorteilen. Zu den beliebten Optionen gehören VOICEAIR, UberTTS, Speechify, NaturalReader und Balabolka.
Wie kann ich die beste Text-to-Speech-Stimme auswählen?
Die meisten Text-to-Speech-Tools bieten eine große Auswahl an Stimmen, die von natürlichen menschlichen Stimmen bis hin zu fortschrittlichen KI-Text-to-Speech-Generatoren reicht. Sie können die KI-Stimme auswählen, die Ihren Vorlieben und Bedürfnissen am besten entspricht, oder Sie können aus einer Sammlung von KI-Stimmen auswählen.
Kann die Text-to-Speech-Technologie verwendet werden, um Text für andere Zwecke in Audio umzuwandeln?
Ja, Text-to-Speech kann verwendet werden, um gedruckten Text für verschiedene Zwecke wie Podcasts, Präsentationen, Videokommentare, Voice-Overs umzuwandeln, sei es für den persönlichen oder kommerziellen Gebrauch.
Was ist der Unterschied zwischen Text-to-Speech und einem Synchronsprecher für Hörbücher?
Während die Text-to-Speech-Technologie eine schnelle und kostengünstige Möglichkeit zur Erstellung von Hörbüchern bieten kann, argumentieren einige, dass ein menschlicher Synchronsprecher ein immersiveres und emotionaleres Hörerlebnis bieten kann.
Wie wirkt sich Text-to-Speech auf das Hörerlebnis von Hörbüchern aus?
Wie jedes Tool kann Text-to-Speech das Hörerlebnis von Hörbüchern verbessern oder beeinträchtigen, abhängig von der Qualität der Stimme, der Genauigkeit der Erzählung und den Vorlieben des Hörers.
Welche Tipps gibt es für den Einsatz von Text-to-Speech für das beste Hörerlebnis?
Einige Tipps für die Verwendung von Text-to-Speech für das beste Hörerlebnis umfassen die Auswahl eines großartigen Text-to-Speech-Tools, die Auswahl einer hochwertigen Stimme und die Anpassung der Geschwindigkeit und des Tons der Sprache an Ihre Vorlieben.

