
Gli audiolibri sono diventati sempre più popolari negli ultimi anni grazie alla loro praticità e compatibilità con gli stili di vita moderni. Che si tratti di ascoltarli durante gli spostamenti quotidiani o mentre si svolgono le faccende domestiche, gli audiolibri consentono alle persone di immergersi nelle loro storie preferite mentre sono in movimento.
Tuttavia, la creazione di un audiolibro richiede in genere un investimento significativo sia in termini di tempo che di denaro. È qui che entra in gioco la tecnologia di sintesi vocale, fornendo una soluzione innovativa sia per autori che per editori.
Cos'è la sintesi vocale?
La sintesi vocale è una tecnologia che consente di convertire il testo scritto in parole pronunciate. Ciò si ottiene attraverso un processo chiamato sintesi vocale, che utilizza vari algoritmi e database vocali per generare un parlato realistico e simile a quello umano. La tecnologia di sintesi vocale è stata utilizzata per una varietà di applicazioni, tra cui la traduzione linguistica, l'accessibilità e ora la creazione di audiolibri.
Come funziona la sintesi vocale?
La sintesi vocale funziona analizzando il testo scritto e suddividendolo in singole unità fonetiche, chiamate fonemi. Questi fonemi vengono poi combinati per creare parole, frasi e, infine, il testo parlato. Software di sintesi vocale utilizza l'apprendimento automatico per migliorare continuamente la precisione e la naturalezza della voce sintetizzata, ottenendo nel tempo voci AI più realistiche.
Componenti di un sistema TTS
Un sistema TTS è costituito da due componenti principali: analisi del testo E sintesi vocale.
- Analisi del testo è il processo di estrazione delle informazioni linguistiche dal testo di input, come la trascrizione fonetica, la prosodia e la punteggiatura. L'analisi del testo può essere ulteriormente suddivisa in due sottocomponenti: normalizzazione del testo e conversione da testo a fonema.
Normalizzazione del testo è il processo di conversione di parole non standard, come numeri, abbreviazioni, acronimi e modi di dire, nelle loro forme complete. Ad esempio, "Dr." diventa "dottore", "10" diventa "dieci" e "LOL" diventa "ridere ad alta voce". La normalizzazione del testo può essere eseguita utilizzando grammatiche o lessici regolari.
Da testo a fonema la conversione è il processo di assegnazione di simboli fonetici a ciascuna parola nel testo, in base alla sua ortografia e al contesto. Ad esempio, “read” può essere pronunciato come /riːd/ o /rɛd/, a seconda del tempo verbale. La conversione da testo a fonema può essere eseguita utilizzando le regole lettera-suono o l'analisi morfosintattica. - Sintesi vocale è il processo di generazione di segnali vocali dalle informazioni linguistiche prodotte dall'analisi del testo. La sintesi vocale può essere eseguita utilizzando vari metodi, come approcci concatenati, parametrici o basati su reti neurali.
Concatenazione è il metodo per unire unità vocali preregistrate, come parole, sillabe o fonemi, per formare un discorso continuo. La qualità della concatenazione dipende dalla dimensione e dalla selezione delle unità vocali, nonché dalle tecniche di livellamento utilizzate per ridurre le discontinuità.
Parametrico è il metodo che utilizza un modello matematico del tratto vocale umano e di altre caratteristiche della voce per generare un parlato sintetico. I parametri del modello derivano dalle informazioni linguistiche e modificati dalle regole della prosodia. La qualità della sintesi parametrica dipende dall'accuratezza e dalla naturalezza del modello.
Rete neurale-based è il metodo che utilizza un algoritmo di deep learning per apprendere la mappatura tra informazioni linguistiche e segnali vocali da un ampio corpus di dati vocali. La rete neurale può generare un parlato di alta qualità e dal suono naturale con un intervento umano minimo. Tuttavia, questo metodo richiede molte risorse computazionali e dati
Quali sono i vantaggi della sintesi vocale?
La tecnologia di sintesi vocale offre un'ampia gamma di vantaggi, in particolare per la creazione di audiolibri. In primo luogo, esso elimina la necessità di costosi studi di registrazione, ingegneri del suono e doppiatori, rendendo il processo di produzione notevolmente più efficiente in termini di costi. Inoltre, la sintesi vocale consente autori ed editori di personalizzare i propri libri in termini di velocità di lettura e persino di accenti, aprendo possibilità per offerte di audiolibri diversificate e inclusive.
Accessibilità e inclusività sono valori importanti per creare una società più equa e diversificata. La tecnologia di sintesi vocale (TTS) può svolgere un ruolo fondamentale nel migliorare l’accessibilità e l’inclusività per un pubblico più ampio, in particolare per gli audiolibri.
TTS è la tecnologia che converte il testo scritto in parlato, utilizzando voci artificiali o naturali. TTS può rendere disponibili audiolibri a persone che potrebbero avere difficoltà a leggere o ad accedere a contenuti scritti, come persone con disabilità visive, dislessia, ADHD o altre disabilità cognitive o di apprendimento.
TTS può anche rendere gli audiolibri più inclusivi per le persone che parlano lingue diverse o hanno accenti diversi, fornendo una varietà di voci e lingue tra cui scegliere.
Alcuni dei vantaggi di TTS per gli audiolibri sono:
- Il TTS può migliorare la comprensione e la memorizzazione delle informazioni, fornendo un rinforzo uditivo del contenuto scritto
- TTS può aumentare il coinvolgimento e il divertimento degli audiolibri, fornendo voci naturali ed espressive che si adattano al tono e all'umore del contenuto
- TTS può ridurre i costi e la complessità della produzione di audiolibri, utilizzando soluzioni automatizzate e scalabili che non richiedono narratori o studi umani
- TTS può espandere la disponibilità e la diversità degli audiolibri, consentendo ad autori ed editori di creare audiolibri per qualsiasi genere, argomento o lingua
TTS è un potente strumento che può rendere gli audiolibri più accessibili e inclusivi per tutti. Utilizzando TTS, gli ascoltatori di audiolibri possono provare la gioia della lettura in un modo che si adatta alle loro esigenze e preferenze.
La sintesi vocale può essere utilizzata per gli audiolibri?
Sì, la tecnologia di sintesi vocale può essere utilizzata per la creazione di audiolibri. Infatti, negli ultimi anni è diventato sempre più popolare grazie alla sua convenienza e versatilità. Con il software di sintesi vocale, qualsiasi contenuto scritto, inclusi libri, PDF, pagine Web e file di testo, può essere facilmente convertito in un file audio, come MP3 o WAV, per un'esperienza audiolibro senza interruzioni.
Come utilizzare il generatore vocale AI per audiolibri
Cos'è un generatore vocale AI?
Un generatore vocale AI è un tipo di software di sintesi vocale che utilizza l'intelligenza artificiale per creare voci più realistiche e dal suono naturale. Generatori vocali AI, come VOICEAIR, UberTTS, Speechify o Lovo, offrono una gamma di personalizzazioni, tra cui velocità di lettura, tono e persino la possibilità di scegliere un accento o una voce specifici in base ai dialetti regionali. I generatori vocali AI consentono una migliore flessibilità vocale, risultando in audiolibri più coinvolgenti.
Quali sono i migliori software di sintesi vocale per audiolibri?
Quando si tratta di selezionare un software di sintesi vocale per audiolibri, sono disponibili diverse opzioni. Alcune delle migliori opzioni software di sintesi vocale includono Polly di Amazon, Text-to-Speech di Google e la funzione di sintesi vocale integrata di Apple. Queste opzioni software consentono ad autori ed editori di convertire facilmente qualsiasi testo in parlato e creare produzioni di audiolibri di alta qualità.
UberTTS è un potente generatore di sintesi vocale per audiolibri che combina le capacità di intelligenza artificiale di Entrambi Amazon Polly E Google Sintesi vocale da testo insieme a Azzurro & IBM voci.
In alternativa puoi utilizzare altri convertitori vocali popolari come:
- NaturalReader: una soluzione basata su cloud che supporta una gamma di file e lingue e consente di scaricare file audio. Ha un livello gratuito e un livello a pagamento con più funzionalità.
- Murf: uno strumento basato sul Web che ti consente di creare voci fuori campo realistiche per i video utilizzando l'intelligenza artificiale. Puoi personalizzare la voce, l'emozione, la velocità e la musica di sottofondo. Ha una prova gratuita e un piano di abbonamento.
- Amazon Polly: un servizio che fornisce voci realistiche utilizzando il deep learning. Puoi usarlo per creare applicazioni e prodotti abilitati alla sintesi vocale, come podcast, corsi di e-learning e giochi. Ha un modello di prezzo a consumo.
- Gioca.ht: una piattaforma che ti aiuta a convertire i post e gli articoli del tuo blog in audio utilizzando voci simili a quelle umane. Puoi incorporare l'audio nel tuo sito web o condividerlo sui social media. Ha un piano gratuito e un piano premium con più vantaggi.
- Lettore di sogni vocali: un'app che legge qualsiasi testo ad alta voce con voci dal suono naturale. Puoi importare documenti da varie fonti, regolare la velocità di lettura e la voce e ascoltare offline. È disponibile per dispositivi iOS e Android.
In che modo AI Voice può aiutarti a creare audiolibri?
AI Voice offre una serie di vantaggi per la creazione di audiolibri, principalmente grazie alla sua capacità di generare un parlato più naturale e realistico. Ciò può comportare un'esperienza di ascolto più piacevole e coinvolgente per il pubblico. Inoltre, la voce AI consente una maggiore velocità ed efficienza nel processo di produzione, poiché non è necessario un ampio editing post-produzione.
Utilizzo del software di sintesi vocale per audiolibri
Quali sono i migliori sintesi vocale per audiolibri?
Come accennato in precedenza, alcuni dei migliori software di sintesi vocale per audiolibri includono Polly di Amazon, Text-to-Speech di Google e la funzione di sintesi vocale integrata di Apple. Inoltre, è disponibile una gamma di opzioni software specializzate di sintesi vocale, come NaturalReader e ReadSpeaker, che offrono opzioni di personalizzazione più avanzate.
In che modo il software di sintesi vocale può aiutarti a personalizzare i tuoi audiolibri?
Il software di sintesi vocale consente ad autori ed editori di personalizzare facilmente le proprie produzioni di audiolibri in vari modi. Ciò include la regolazione della velocità di lettura, del tono e del volume per creare un'esperienza di ascolto ottimale. Inoltre, il software di sintesi vocale consente l'utilizzo di diversi accenti e dialetti regionali, rendendo l'audiolibro più accessibile e inclusivo.
Il software Text to Speech può aiutarti a creare audiolibri dal suono naturale con accenti diversi?
Sì, il software di sintesi vocale può aiutare a creare audiolibri dal suono naturale con accenti diversi. Ciò si ottiene utilizzando database vocali che includono una gamma di dialetti regionali e opzioni di accento. Ciò consente una maggiore flessibilità vocale e una selezione più diversificata di audiolibri per il pubblico.
Converti testo in audiolibri
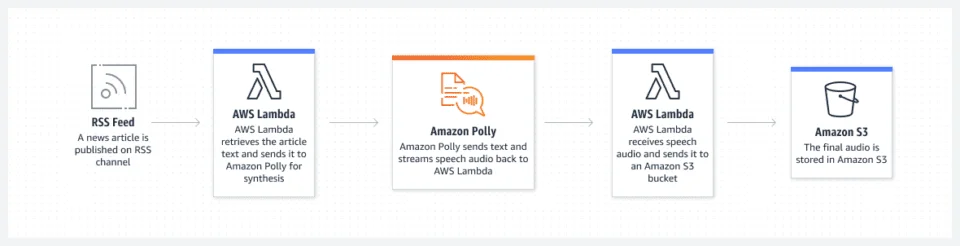 Pin
PinCome convertire i PDF in audiolibri utilizzando la tecnologia Text to Speech?
Convertire PDF in audiolibri utilizzando la tecnologia di sintesi vocale è un processo semplice. Innanzitutto, seleziona il tuo software di sintesi vocale preferito e carica il documento PDF. Il software analizzerà quindi il testo e lo convertirà in parole pronunciate, creando un file audio che potrà essere scaricato in diversi formati. Ciò consente alle persone di convertire facilmente i contenuti scritti in un formato audiolibro per un'esperienza di lettura più versatile.
Quali sono le migliori piattaforme di audiolibri per l'utilizzo della tecnologia Text to Speech?
Esistono numerose piattaforme di audiolibri compatibili con la tecnologia di sintesi vocale. Una delle opzioni più popolari è Audible di proprietà di Amazon. Audible offre una gamma di audiolibri compatibili con il software di sintesi vocale, consentendo un'esperienza di ascolto più personalizzabile. Altre piattaforme popolari includono Apple Books e Google Play Books.
Quali sono i vantaggi dell'utilizzo degli audiolibri con la tecnologia Text to Speech?
Esistono numerosi vantaggi nell'utilizzo di audiolibri con la tecnologia di sintesi vocale. In primo luogo, consente alle persone di convertire facilmente qualsiasi contenuto scritto in un formato audio per una maggiore accessibilità. In secondo luogo, la tecnologia di sintesi vocale consente una maggiore flessibilità vocale e può creare audiolibri dal suono naturale con accenti diversi, risultando in una selezione di audiolibri più inclusiva e diversificata per il pubblico.
Migliori pratiche per l'utilizzo della sintesi vocale nella produzione di audiolibri
Di seguito sono riportate alcune possibili migliori pratiche per l'utilizzo della sintesi vocale nella produzione di audiolibri:
Scegli uno strumento di sintesi vocale che offra una varietà di voci dal suono naturale ed espressivo adatte al genere, al pubblico e allo scopo dell'audiolibro. Puoi anche personalizzare le funzionalità vocali come tono, tono, velocità e volume per adattarle all'umore e all'emozione del testo.
Converti il contenuto scritto in un formato audio utilizzando un sintetizzatore vocale. Questo ti darà un'idea di come suona il testo e identificherà eventuali errori, incongruenze o ambiguità che necessitano di essere corrette o chiarite3. Puoi anche utilizzare l'audio come riferimento per la tua narrazione o editing.
Modifica il contenuto audio per migliorarne la qualità e la chiarezza. È possibile utilizzare un software di editing audio per ritagliare, tagliare, unire, unire o regolare i segmenti audio. Puoi anche aggiungere effetti sonori, musica o rumore di sottofondo per creare un'esperienza di ascolto più coinvolgente e realistica.
Testa il contenuto audio con diversi dispositivi, piattaforme e ascoltatori. Puoi utilizzare cuffie, altoparlanti o lettori multimediali diversi per verificare la qualità del suono e la compatibilità del contenuto audio. Puoi anche chiedere feedback a potenziali ascoltatori o esperti per valutare l'efficacia e l'attrattiva del contenuto audio.
Combinazione di sintesi vocale e narrazione umana per audiolibri
La combinazione di sintesi vocale e narrazione umana per gli audiolibri è un argomento che esplora come utilizzare l'intelligenza artificiale per creare audiolibri di alta qualità da file di testo. È una tecnologia che può rendere la produzione di audiolibri più accessibile, conveniente e diversificata per autori ed editori. Alcuni esempi di servizi che offrono questa tecnologia sono Narrazione digitale di Apple Books E Audiolibri con narratore automatico di Google Play Libri.
Questi servizi utilizzano la sintesi vocale avanzata e l'elaborazione del linguaggio naturale per generare voci realistiche ed espressive in grado di narrare diversi generi di libri. Consentono inoltre agli autori e agli editori di mantenere i diritti sui propri audiolibri e di distribuirli attraverso varie piattaforme.
Tuttavia, questi servizi devono affrontare anche alcune sfide e limitazioni, come garantire l’accuratezza, la qualità e la coerenza della narrazione, rispettare le scelte creative e le preferenze degli autori e dei narratori e competere con il mercato degli audiolibri narrati da esseri umani che ancora valorizza la magia. e l'arte delle voci umane.
Comprendere l'approccio ibrido: integrare TTS e narrazione umana nella produzione di audiolibri.
L'approccio ibrido: Integrating TTS and human narration in audiobook production è un documento di ricerca che propone un nuovo metodo per combinare due tipi di sintesi text-to-speech (TTS): TTS concatenativo (CTTS) e TTS statistico (STTS). CTTS utilizza segmenti vocali naturali da un database registrato, mentre STTS genera caratteristiche vocali da un modello statistico.
L'articolo sostiene che il CTTS può produrre un parlato naturale e di alta qualità, ma potrebbe soffrire di discontinuità e limitazioni dei dati. D'altra parte, l'STTS può produrre un parlato fluido e coerente, ma può sembrare ovattato e innaturale.
L'articolo suggerisce che utilizzando un algoritmo di percorso dinamico ibrido, è possibile costruire una rappresentazione dell'enunciato che intreccia segmenti naturali e segmenti generati dal modello, sfruttando così entrambi gli approcci. Nell'elaborato sono riportate prove di ascolto che dimostrano la validità e l'efficacia del metodo proposto.
Vantaggi dell'utilizzo di TTS come strumento di stesura e correzione per narratori umani
L'utilizzo di TTS come strumento di stesura e correzione per narratori umani può avere diversi vantaggi, tra cui:
- Può aiutare i narratori umani a preparare e mettere in pratica i propri script prima della registrazione, consentendo loro di ascoltare come suona il testo e identificare eventuali errori, incoerenze o ambiguità che devono essere corretti o chiariti.
- Può aiutare i narratori umani a migliorare le loro prestazioni e la loro interpretazione, fornendo loro feedback sulla pronuncia, intonazione, ritmo ed espressione e suggerendo modi per migliorare la qualità della voce e le emozioni.
- Può aiutare i narratori umani a risparmiare tempo e denaro, riducendo la necessità di molteplici registrazioni e modifiche e consentendo loro di lavorare in remoto e in collaborazione con altri narratori, editori e produttori.
- Può aiutare i narratori umani a creare audiolibri più diversificati e inclusivi, consentendo loro di sperimentare voci, accenti, lingue e stili diversi che si adattano al genere, al pubblico e allo scopo dell'audiolibro
Raggiungere una fusione perfetta: strategie per combinare efficacemente TTS e narrazione umana
Alcune possibili strategie per combinare efficacemente TTS e narrazione umana sono:
- Utilizzare TTS come strumento di stesura e correzione per narratori umani, consentendo loro di ascoltare come suona il testo e identificare eventuali errori, incoerenze o ambiguità che devono essere corretti o chiariti1. TTS può anche fornire feedback su pronuncia, intonazione, ritmo ed espressione e suggerire modi per migliorare la qualità della voce e le emozioni.
- Utilizza TTS come base per i contenuti audio, che possono poi essere migliorati con l'aggiunta di doppiatori umani. I doppiatori umani possono apportare un livello di autenticità e personalizzazione ai contenuti audio che non è possibile ottenere tramite il solo TTS. Possono interpretare sceneggiature e trasmettere toni e sfumature emotive difficili da catturare con TTS. I doppiatori umani possono anche adattare la propria erogazione in base al feedback del pubblico, il che migliora ulteriormente la personalizzazione e l'efficacia del contenuto audio.
- Utilizza TTS per generare una traccia narrativa di base per contenuti multimediali, che può poi essere personalizzata e migliorata con l'aggiunta di doppiatori umani in varie lingue. Questo approccio semplifica il processo di localizzazione e riduce i costi di produzione, offrendo allo stesso tempo contenuti audio personalizzati e di alta qualità al pubblico globale.
Esempi di audiolibri di successo che utilizzano l'approccio ibrido
Diamo un'occhiata ad alcuni possibili esempi di audiolibri di fantascienza che utilizzano l'approccio ibrido:
- Migliora l'anima di Ezra Claytan Daniels, narrato da Marcia Gay Harden, Wendell Pierce e altri. Si tratta di un adattamento audio di una graphic novel che utilizza un mix di segmenti vocali naturali e segmenti generati da modelli per creare una narrazione realistica ed espressiva. La storia segue una coppia di anziani che si sottopone a una procedura sperimentale per ringiovanire il proprio corpo e la propria mente, ma i risultati sono terrificanti..
- Quanto in alto andiamo nel buio di Sequoia Nagamatsu, narrato da un cast completo. Questo è un romanzo di fantascienza che utilizza un cast completo di doppiatori per dare vita a molteplici storie, personaggi e luoghi che si interconnettono in modi complessi e soddisfacenti. La storia attraversa secoli e continenti, esplorando il modo in cui l’umanità affronta una pandemia che fa sì che le persone emettano luce quando muoiono.
- Gedeone IX di Tamsyn Muir, narrato da Moira Quirk. Questo è un romanzo fantasy di fantascienza che utilizza un singolo doppiatore per offrire una performance straordinaria che cattura l'umorismo, l'orrore e il cuore della storia. La storia segue Gideon, una spadaccina che accompagna la sua amante negromante in un palazzo infestato dove devono competere con altri negromanti per un premio.
L'approccio ibrido migliora questi audiolibri creando un'esperienza di ascolto più coinvolgente e coinvolgente per il pubblico. Combinando segmenti del parlato naturale e segmenti generati dal modello, l'approccio ibrido può produrre un parlato naturale e di alta qualità che si adatta al tono e all'umore della storia.
Utilizzando un cast completo di doppiatori, l'approccio ibrido può creare un contenuto audio diversificato e inclusivo che riflette la varietà di personaggi e prospettive della storia. Utilizzando un singolo doppiatore, l'approccio ibrido può creare un contenuto audio personalizzato ed emotivamente ricco di sfumature che trasmette la personalità e la voce del narratore.
L’approccio ibrido può anche rendere gli audiolibri più accessibili e adattabili a diversi linguaggi, piattaforme e dispositivi.
Come sarà il futuro degli audiolibri con l'intelligenza artificiale?
In che modo l’intelligenza artificiale può migliorare gli audiolibri in futuro?
L’intelligenza artificiale ha il potenziale per migliorare significativamente l’esperienza dell’audiolibro in vari modi. In primo luogo, l’intelligenza artificiale può aiutare a creare voci e accenti dal suono ancora più naturale, risultando in un’esperienza di ascolto più coinvolgente e realistica.
Inoltre, l'intelligenza artificiale ha la capacità di ottimizzare dinamicamente gli audiolibri in base alle preferenze dell'ascoltatore, ad esempio regolando la velocità o il tono di lettura.
Infine, l’intelligenza artificiale ha la capacità di personalizzare l’esperienza dell’audiolibro, creando produzioni uniche su misura per i singoli ascoltatori in base alla loro cronologia di ascolto e alle loro preferenze.
Quali novità ci si possono aspettare nel 2023?
È difficile prevedere esattamente quali nuove funzionalità verranno rilasciate nel 2023, ma si può presumere che l’intelligenza artificiale continuerà a svolgere un ruolo significativo nell’evoluzione degli audiolibri. Le nuove funzionalità potrebbero includere database vocali migliorati, maggiore flessibilità vocale e strumenti di editing post-produzione migliorati per esperienze di ascolto ancora più su misura e personalizzate.
I doppiatori saranno sostituiti da voci generate dall’intelligenza artificiale?
Sebbene le voci generate dall’intelligenza artificiale stiano diventando sempre più realistiche, è improbabile che sostituiranno completamente i doppiatori nel prossimo futuro. I doppiatori offrono ancora una serie di vantaggi, tra cui una maggiore profondità emotiva e versatilità nelle loro performance.
Tuttavia, le voci generate dall’intelligenza artificiale continueranno a svolgere un ruolo importante nella produzione di audiolibri, in particolare con contenuti più tecnici o educativi in cui il parlato dal suono naturale è una priorità rispetto alle caratteristiche vocali uniche.
Domande frequenti (FAQ)
Cos'è la sintesi vocale?
La sintesi vocale è una tecnologia che consente la conversione del testo scritto in parole parlate.
Come funziona la sintesi vocale per gli audiolibri?
La tecnologia di sintesi vocale può essere utilizzata per trasformare il testo di un e-book o PDF in un file audio che può essere riprodotto come audiolibro. Ciò può fornire un'esperienza di ascolto accessibile a coloro che preferiscono ascoltare piuttosto che leggere o che hanno problemi di vista.
Quali sono i vantaggi dell'utilizzo della sintesi vocale per gli audiolibri?
La sintesi vocale può offrire un modo più rapido e conveniente per ascoltare gli audiolibri. Consente una maggiore personalizzazione, poiché gli ascoltatori possono scegliere la voce e la velocità della narrazione e possono anche mettere in pausa, riavvolgere o saltare le sezioni secondo necessità.
Come posso utilizzare la tecnologia di sintesi vocale per creare i miei audiolibri?
Sono disponibili vari strumenti e software che consentono la facile conversione del testo in parlato. Alcuni potrebbero richiedere un canone o un abbonamento, mentre altri potrebbero essere gratuiti o open source.
Qual è il miglior strumento di sintesi vocale per gli audiolibri?
Sul mercato sono disponibili numerosi strumenti di sintesi vocale, ciascuno con caratteristiche e vantaggi unici. Alcune opzioni popolari includono VOICEAIR, UberTTS, Speechify, NaturalReader e Balabolka.
Come posso scegliere la migliore voce per la sintesi vocale?
La maggior parte degli strumenti di sintesi vocale offre un'ampia selezione di voci tra cui scegliere, che vanno dalle voci umane naturali ai generatori di sintesi vocale avanzati AI. Puoi selezionare la voce AI che meglio si adatta alle tue preferenze ed esigenze oppure puoi scegliere da una raccolta di voci AI.
La tecnologia di sintesi vocale può essere utilizzata per convertire testo in audio per altri scopi?
Sì, la sintesi vocale può essere utilizzata per trasformare il testo stampato per diversi scopi come podcast, presentazioni, narrazioni video, voci fuori campo, sia per uso personale che commerciale.
Qual è la differenza tra sintesi vocale e doppiatore per gli audiolibri?
Sebbene la tecnologia di sintesi vocale possa fornire un modo rapido ed economico per creare audiolibri, alcuni sostengono che un doppiatore umano possa fornire un'esperienza di ascolto più coinvolgente ed emozionante.
In che modo la sintesi vocale influisce sull'esperienza di ascolto degli audiolibri?
Come ogni strumento, la sintesi vocale può migliorare o diminuire l'esperienza di ascolto degli audiolibri a seconda della qualità della voce, dell'accuratezza della narrazione e delle preferenze dell'ascoltatore.
Quali sono alcuni suggerimenti per utilizzare la sintesi vocale per la migliore esperienza di ascolto?
Alcuni suggerimenti per utilizzare la sintesi vocale per la migliore esperienza di ascolto includono la selezione di un ottimo strumento di sintesi vocale, la scelta di una voce di alta qualità e la regolazione della velocità e del tono del discorso in base alle proprie preferenze.


